Panda untuk Analisis Numerik
Pandas dikembangkan karena kebutuhan akan cara yang efisien untuk mengelola data keuangan dengan Python. Pandas adalah perpustakaan yang dapat diimpor ke python untuk membantu memanipulasi dan mengubah data numerik. Wes McKinney memulai proyek ini pada tahun 2008. Pandas sekarang dikelola oleh sekelompok insinyur dan didukung oleh NUMFocus nonprofit, yang akan memastikan pertumbuhan dan perkembangannya di masa depan. Ini berarti panda akan menjadi perpustakaan yang stabil selama bertahun-tahun dan dapat dimasukkan ke dalam aplikasi Anda tanpa khawatir dengan proyek kecil.
Meskipun panda awalnya dikembangkan untuk memodelkan data keuangan, struktur datanya dapat digunakan untuk memanipulasi berbagai data numerik numerical. Panda memiliki sejumlah struktur data yang terintegrasi dan dapat digunakan untuk memodelkan dan memanipulasi data numerik dengan mudah. Tutorial ini akan membahas panda Bingkai Data struktur data secara mendalam.
Apa itu DataFrame??
SEBUAH Bingkai Data adalah salah satu struktur data utama dalam panda dan mewakili kumpulan data 2-D. Ada banyak objek analog dengan jenis struktur data 2-D ini, beberapa di antaranya termasuk spreadsheet Excel yang selalu populer, tabel database, atau larik 2-D yang ditemukan di sebagian besar bahasa pemrograman. Di bawah ini adalah contoh Bingkai Data dalam format grafik. Ini mewakili sekelompok deret waktu harga penutupan saham berdasarkan tanggal.
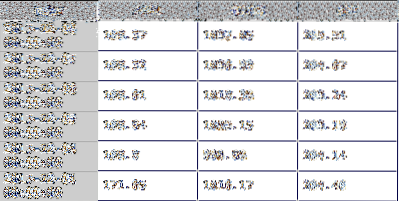
Tutorial ini akan memandu Anda melalui banyak metode kerangka data dan saya akan menggunakan model keuangan dunia nyata untuk mendemonstrasikan fungsi-fungsi ini.
Mengimpor Data
Kelas Panda memiliki beberapa metode bawaan untuk membantu mengimpor data ke dalam struktur data. Di bawah ini adalah contoh cara mengimpor data ke Panel pandas dengan Pembaca Data kelas. Ini dapat digunakan untuk mengimpor data dari beberapa sumber data keuangan gratis termasuk Quandl, Yahoo Finance dan Google. Untuk menggunakan perpustakaan pandas, Anda perlu menambahkannya sebagai impor dalam kode Anda.
impor panda sebagai pdMetode di bawah ini akan memulai program dengan menjalankan metode menjalankan tutorial.
jika __name__ == "__main__":tutorial_run()
Itu tutorial_run caranya ada di bawah. Ini adalah metode selanjutnya yang akan saya tambahkan ke kode. Baris pertama dari metode ini mendefinisikan daftar ticker saham. Variabel ini nantinya akan digunakan dalam kode sebagai daftar stok yang akan diminta datanya untuk mengisi Bingkai Data. Baris kode kedua memanggil get_data metode. Seperti yang akan kita lihat, get_data metode mengambil tiga parameter sebagai inputnya. Kami akan melewati daftar ticker saham, tanggal mulai, dan tanggal akhir untuk data yang akan kami minta.
def tutorial_run():#Stock Tickers untuk sumber dari Yahoo Finance
simbol = ['SPY', 'AAPL','GOOG']
#dapatkan data
df = get_data(simbol, '2006-01-03', '2017-12-31')
Di bawah ini kita akan mendefinisikan get_data metode. Seperti yang saya sebutkan di atas, dibutuhkan tiga parameter daftar simbol, tanggal mulai dan berakhir.
Baris kode pertama mendefinisikan panel pandas dengan membuat instance a Pembaca Data kelas. Panggilan untuk Pembaca Data kelas akan terhubung ke server Yahoo Finance dan meminta nilai penutupan tertinggi, terendah, penutupan, dan penyesuaian harian untuk setiap ekuitas di simbol daftar. Data ini dimuat ke objek panel oleh panda panda.
SEBUAH panel adalah matriks 3-D dan dapat dianggap sebagai "tumpukan" dari DataFrame. Setiap Bingkai Data di tumpukan berisi salah satu nilai harian untuk stok dan rentang tanggal yang diminta. Misalnya, di bawah ini Bingkai Data, disajikan sebelumnya, adalah harga penutupan Bingkai Data dari permintaan. Setiap jenis harga (tinggi, rendah, tutup, dan tutup yang disesuaikan) memilikinya sendiri Bingkai Data di panel yang dihasilkan dikembalikan dari permintaan.
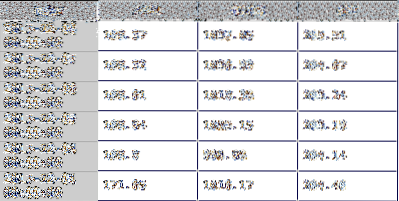
Baris kedua kode mengiris panel menjadi satu Bingkai Data dan menetapkan data yang dihasilkan ke df. Ini akan menjadi variabel saya untuk Bingkai Data yang saya gunakan untuk sisa tutorial. Ini memegang nilai penutupan harian untuk tiga ekuitas untuk rentang tanggal yang ditentukan. Panel diiris dengan menentukan panel mana DataFrame kamu ingin kembali. Dalam contoh baris kode di bawah ini, itu adalah 'Tutup'.
Setelah kita memiliki Bingkai Data sebagai gantinya, saya akan membahas beberapa fungsi yang berguna di perpustakaan pandas yang memungkinkan kita untuk memanipulasi data di Bingkai Data obyek.
def get_data(simbol, tanggal_mulai, tanggal_akhir):panel = data.Pembaca Data(simbol, 'yahoo', tanggal_mulai, tanggal_akhir)
df = panel['Tutup']
cetak(df.kepala(5))
cetak(df.ekor (5))
kembali df
Kepala dan ekor
Baris ketiga dan keempat dari get_data cetak kepala fungsi dan ekor bingkai data. Saya menemukan ini paling berguna dalam debugging dan visualisasi data, tetapi juga dapat digunakan untuk memilih sampel pertama atau terakhir dari data di Bingkai Data. Fungsi kepala dan ekor menarik baris data pertama dan terakhir dari Bingkai Data. Parameter integer antara tanda kurung mendefinisikan jumlah baris yang akan dipilih oleh metode.
.lokasi
Itu Bingkai Data lokasi metode mengiris Bingkai Data berdasarkan indeks. Baris kode di bawah ini mengiris df Bingkai Data menurut indeks 2017-12-12. Saya telah memberikan tangkapan layar hasil di bawah ini.
cetak df.lokasi["2017-12-12"]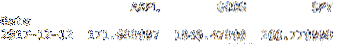
lokasi dapat digunakan sebagai irisan dua dimensi juga. Parameter pertama adalah baris dan parameter kedua adalah kolom. Kode di bawah ini mengembalikan nilai tunggal yang sama dengan harga penutupan Apple pada 12/12/2014.
cetak df.loc["2017-12-12", "AAPL" ]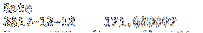
Itu lokasi metode dapat digunakan untuk mengiris semua baris dalam kolom atau semua kolom dalam satu baris. Itu : operator digunakan untuk menunjukkan semua. Baris kode di bawah ini memilih semua baris di kolom untuk harga penutupan Google.
cetak df.lokasi[: , "GOOG" ]
.mengisi
Adalah umum, terutama dalam kumpulan data keuangan, untuk memiliki nilai NaN di . Anda Bingkai Data. Pandas menyediakan fungsi untuk mengisi nilai-nilai ini dengan nilai numerik. Ini berguna jika Anda ingin melakukan semacam perhitungan pada data yang mungkin miring atau gagal karena nilai NaN.
Itu .mengisi metode akan menggantikan nilai yang ditentukan untuk setiap nilai NaN dalam kumpulan data Anda. Baris kode di bawah ini akan mengisi semua NaN di kami Bingkai Data dengan 0. Nilai default ini dapat diubah untuk nilai yang memenuhi kebutuhan kumpulan data yang sedang Anda kerjakan dengan memperbarui parameter yang diteruskan ke metode.
df.isi(0)Normalisasi Data
Saat menggunakan pembelajaran mesin atau algoritme analisis keuangan, seringkali berguna untuk menormalkan nilai Anda. Metode di bawah ini adalah perhitungan yang efisien untuk menormalkan data dalam panda Bingkai Data. Saya mendorong Anda untuk menggunakan metode ini karena kode ini akan berjalan lebih efisien daripada metode lain untuk normalisasi dan dapat menunjukkan peningkatan kinerja yang besar pada kumpulan data yang besar.
.iloc adalah metode yang mirip dengan .lokasi tetapi mengambil parameter berbasis lokasi daripada parameter berbasis tag. Dibutuhkan indeks berbasis nol daripada nama kolom dari .lokasi contoh. Kode normalisasi di bawah ini adalah contoh dari beberapa perhitungan matriks yang kuat yang dapat dilakukan. Saya akan melewatkan pelajaran aljabar linier, tetapi pada dasarnya baris kode ini akan membagi seluruh matriks atau Bingkai Data dengan nilai pertama dari setiap deret waktu. Bergantung pada kumpulan data Anda, Anda mungkin menginginkan norma berdasarkan min, maks, atau mean. Norma-norma ini juga dapat dengan mudah dihitung menggunakan gaya berbasis matriks di bawah ini:.
def normalize_data(df):kembali df / df.iloc [0,:]
Merencanakan Data
Saat bekerja dengan data, seringkali perlu untuk merepresentasikannya secara grafis. Metode plot memungkinkan Anda dengan mudah membuat grafik dari kumpulan data Anda.
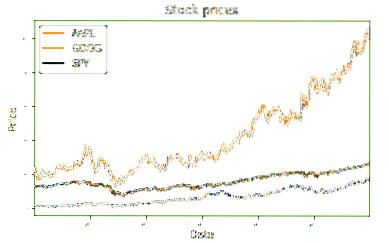
Metode di bawah ini mengambil Bingkai Data dan memplotnya pada grafik garis standar. Metode ini membutuhkan Bingkai Data dan judul sebagai parameternya. Baris pertama dari kumpulan kode kapak ke sebidang DataFrame df. Ini mengatur judul dan ukuran font untuk teks. Dua baris berikut mengatur label untuk sumbu x dan y. Baris kode terakhir memanggil metode show yang mencetak grafik ke konsol. Saya telah memberikan tangkapan layar hasil dari plot di bawah ini. Ini mewakili harga penutupan yang dinormalisasi untuk masing-masing ekuitas selama periode waktu yang dipilih.
def plot_data(df, title="Harga saham"):kapak = df.plot(judul = judul, ukuran font = 2)
kapak.set_xlabel("Tanggal")
kapak.set_ylabel("Harga")
merencanakan.menunjukkan()
Pandas adalah perpustakaan manipulasi data yang kuat. Ini dapat digunakan untuk berbagai jenis data dan menyajikan serangkaian metode yang ringkas dan efisien untuk memanipulasi kumpulan data Anda. Di bawah ini saya telah menyediakan kode lengkap dari tutorial sehingga Anda dapat meninjau dan mengubah untuk memenuhi kebutuhan Anda. Ada beberapa metode lain yang membantu Anda dengan manipulasi data dan saya mendorong Anda untuk meninjau dokumen panda yang diposting di halaman referensi di bawah. NumPy dan MatPlotLib adalah dua perpustakaan lain yang bekerja dengan baik untuk ilmu data dan dapat digunakan untuk meningkatkan kekuatan perpustakaan pandas.
Kode Lengkap
impor panda sebagai pddef plot_selected(df, kolom, start_index, end_index):
plot_data(df.ix[start_index:end_index, kolom])
def get_data(simbol, tanggal_mulai, tanggal_akhir):
panel = data.Pembaca Data(simbol, 'yahoo', tanggal_mulai, tanggal_akhir)
df = panel['Tutup']
cetak(df.kepala(5))
cetak(df.ekor (5))
cetak df.lokasi["2017-12-12"]
cetak df.loc["2017-12-12", "AAPL" ]
cetak df.lokasi[: , "GOOG" ]
df.isi(0)
kembali df
def normalize_data(df):
kembali df / df.ix[0,:]
def plot_data(df, title="Harga saham"):
kapak = df.plot(judul = judul, ukuran font = 2)
kapak.set_xlabel("Tanggal")
kapak.set_ylabel("Harga")
merencanakan.menunjukkan()
def tutorial_run():
#Pilih simbol
simbol = ['SPY', 'AAPL','GOOG']
#dapatkan data
df = get_data(simbol, '2006-01-03', '2017-12-31')
plot_data(df)
jika __name__ == "__main__":
tutorial_run()
Referensi
Halaman Beranda Panda
Halaman Wikipedia Panda
https://en.wikipedia.org/wiki/Wes_McKinney
Halaman Beranda NumFocus


