Dalam pelajaran ini, itulah yang ingin kami lakukan. Kami akan mencari tahu bagaimana nilai tag HTML yang berbeda dapat diekstraksi dan juga mengesampingkan fungsionalitas default modul ini untuk menambahkan beberapa logika kita sendiri. Kami akan melakukan ini menggunakan HTMLParser kelas dengan Python di html.pengurai modul. Mari kita lihat kodenya beraksi.
Melihat kelas HTMLParser
Untuk mengurai teks HTML dengan Python, kita dapat menggunakan HTMLParser masuk kelas html.pengurai modul. Mari kita lihat definisi kelas untuk HTMLParser kelas:
kelas html.pengurai.HTMLParser(*, convert_charrefs=Benar)Itu convert_charrefs bidang, jika disetel ke True akan membuat semua referensi karakter dikonversi ke padanan Unicode mereka. Hanya naskah/gaya elemen tidak dikonversi. Sekarang, kita akan mencoba memahami setiap fungsi untuk kelas ini juga untuk lebih memahami apa yang dilakukan setiap fungsi.
- handle_startendtag Ini adalah fungsi pertama yang dipicu ketika string HTML diteruskan ke instance kelas. Setelah teks sampai di sini, kontrol diteruskan ke fungsi lain di kelas yang dipersempit ke tag lain di String. Ini juga jelas dalam definisi untuk fungsi ini: def handle_startendtag(self, tag, attrs):
diri.handle_starttag(tag, attrs)
diri.handle_endtag(tag) - handle_starttag: Metode ini mengelola tag awal untuk data yang diterimanya. Definisinya adalah seperti yang ditunjukkan di bawah ini: def handle_starttag(self, tag, attrs):
lulus - handle_endtag: Metode ini mengelola tag akhir untuk data yang diterimanya: def handle_endtag(self, tag):
lulus - handle_charref: Metode ini mengelola referensi karakter dalam data yang diterimanya. Definisinya adalah seperti yang ditunjukkan di bawah ini: def handle_charref(self, name):
lulus - handle_entityref: Fungsi ini menangani referensi entitas dalam HTML yang diteruskan ke sana: def handle_entityref(self, name):
lulus - handle_data: Ini adalah fungsi di mana pekerjaan nyata dilakukan untuk mengekstrak nilai dari tag HTML dan meneruskan data yang terkait dengan setiap tag. Definisinya adalah seperti yang ditunjukkan di bawah ini: def handle_data(self, data):
lulus - handle_comment: Dengan menggunakan fungsi ini, kita juga bisa mendapatkan komentar yang dilampirkan ke sumber HTML: def handle_comment(self, data):
lulus - handle_pi: Karena HTML juga dapat memiliki instruksi pemrosesan, ini adalah fungsi di mana definisinya adalah seperti yang ditunjukkan di bawah ini: def handle_pi(self, data):
lulus - handle_decl: Metode ini menangani deklarasi dalam HTML, definisinya diberikan sebagai: def handle_decl(self, decl):
lulus
Mensubklasifikasikan kelas HTMLParser
Di bagian ini, kita akan membuat sub-kelas kelas HTMLParser dan akan melihat beberapa fungsi yang dipanggil ketika data HTML diteruskan ke instance kelas. Mari kita menulis skrip sederhana yang melakukan semua ini:
dari html.pengurai mengimpor HTMLParserkelas LinuxHTMLParser(HTMLParser):
def handle_starttag (diri, tag, attrs):
print("Tag awal ditemukan:", tag)
def handle_endtag(diri, tag):
print("Tag akhir ditemukan :", tag)
def handle_data(sendiri, data):
print("Data ditemukan :", data)
parser = LinuxHTMLParser()
pengurai.makan("
'
Modul penguraian HTML Python
')
Inilah yang kami dapatkan kembali dengan perintah ini:
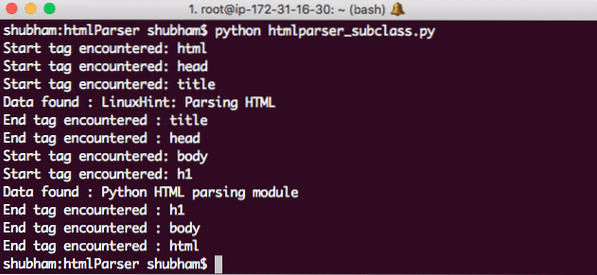
Subkelas Python HTMLParser
Fungsi HTMLParser
Di bagian ini, kita akan bekerja dengan berbagai fungsi kelas HTMLParser dan melihat fungsionalitas masing-masing:
dari html.pengurai mengimpor HTMLParserdari html.entitas mengimpor name2codepoint
kelas LinuxHint_Parse(HTMLParser):
def handle_starttag (diri, tag, attrs):
print("Tag Awal:", tanda)
untuk attr di attrs:
print("attr:", attr)
def handle_endtag(diri, tag):
print("Tag Akhir :", tanda)
def handle_data(sendiri, data):
print("Data :", data)
def handle_comment(diri, data):
print("Komentar :", data)
def handle_entityref(diri sendiri, nama):
c = chr(nama2codepoint[nama])
print("Bernama ent:", c)
def handle_charref(diri sendiri, nama):
jika nama.dimulai dengan('x'):
c = chr(int(nama[1:], 16))
lain:
c = chr(int(nama))
print("Bilangan :", c)
def handle_decl(diri, data):
print("Des:", data)
parser = LinuxHint_Parse()
Dengan berbagai panggilan, mari kita masukkan data HTML terpisah ke instance ini dan lihat output apa yang dihasilkan panggilan ini these. Kita akan mulai dengan yang sederhana DOCTYPE tali:
pengurai.makan(''"http://www.w3.org/TR/html4/strict.dtd">')Inilah yang kami dapatkan kembali dengan panggilan ini:
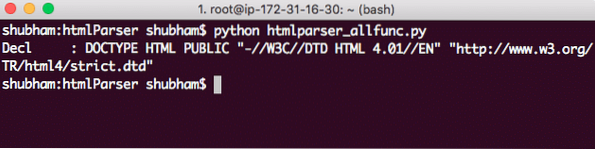
DOCTYPE String
Sekarang mari kita coba tag gambar dan lihat data apa yang diekstraknya:
pengurai.makan(' ')
') Inilah yang kami dapatkan kembali dengan panggilan ini:

Tag gambar HTMLParser
Selanjutnya, mari kita coba bagaimana tag skrip berperilaku dengan fungsi Python:
pengurai.makan('')pengurai.makan('')
pengurai.feed('#python warna: hijau ')
Inilah yang kami dapatkan kembali dengan panggilan ini:

Tag skrip di htmlparser
Terakhir, kami juga memberikan komentar ke bagian HTMLParser:
pengurai.makan('''')
Inilah yang kami dapatkan kembali dengan panggilan ini:

Mengurai komentar
Kesimpulan
Dalam pelajaran ini, kita melihat bagaimana kita dapat mengurai HTML menggunakan kelas HTMLParser Python sendiri tanpa perpustakaan lain. Kami dapat dengan mudah memodifikasi kode untuk mengubah sumber data HTML menjadi klien HTTP.
Baca lebih banyak posting berbasis Python di sini.


