Data besar adalah data dalam urutan terabyte atau petabyte dan seterusnya, terdiri dari penambangan, analisis, dan pemodelan prediktif dari kumpulan data besar. Pesatnya pertumbuhan informasi dan perkembangan teknologi telah memberikan kesempatan unik bagi individu dan perusahaan di seluruh dunia untuk memperoleh keuntungan dan mengembangkan kemampuan baru mendefinisikan ulang model bisnis tradisional menggunakan analitik skala besar.
Artikel ini memberikan pandangan sekilas tentang lima platform data sumber terbuka paling populer. Berikut daftar kami:
Apache Hadoop
Apache Hadoop adalah platform perangkat lunak sumber terbuka yang memproses kumpulan data yang sangat besar dalam lingkungan terdistribusi sehubungan dengan penyimpanan dan daya komputasi, dan terutama dibangun di atas perangkat keras komoditas berbiaya rendah.
Apache Hadoop dirancang untuk meningkatkan skala dari beberapa hingga ribuan server dengan mudah. Ini membantu Anda memproses data yang disimpan secara lokal dalam pengaturan pemrosesan paralel secara keseluruhan. Salah satu manfaat Hadoop adalah menangani kegagalan pada tingkat perangkat lunak. Gambar berikut mengilustrasikan keseluruhan arsitektur Ekosistem Hadoop dan di mana kerangka kerja yang berbeda berada di dalamnya:
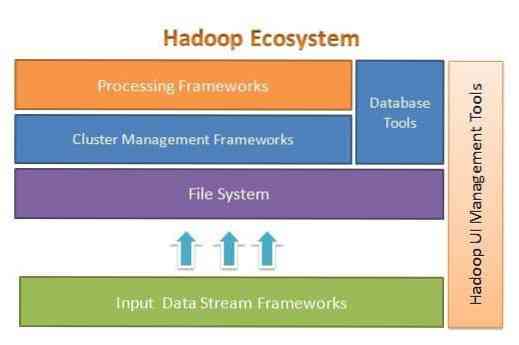
Apache Hadoop menyediakan kerangka kerja untuk lapisan sistem file, lapisan manajemen klaster, dan lapisan pemrosesan. Ini meninggalkan pilihan untuk proyek dan kerangka kerja lain untuk datang dan bekerja bersama Ekosistem Hadoop dan mengembangkan kerangka kerja mereka sendiri untuk setiap lapisan yang tersedia dalam sistem.
Apache Hadoop terdiri dari empat modul utama. Modul-modul ini adalah Hadoop Distributed File System (lapisan sistem file), Hadoop MapReduce (yang bekerja dengan manajemen cluster dan lapisan pemrosesan), Yet Another Resource Negotiator (YARN, lapisan manajemen cluster), dan Hadoop Common.
pencarian elastis
Elasticsearch adalah mesin analitik dan pencarian berbasis teks lengkap. Ini adalah sistem yang sangat skalabel dan terdistribusi, dirancang khusus untuk bekerja secara efisien dan cepat dengan sistem data besar, di mana salah satu kasus penggunaan utamanya adalah analisis log. Ia mampu melakukan pencarian lanjutan dan kompleks, dan pemrosesan hampir real-time untuk analitik canggih dan kecerdasan operasional.
Elasticsearch ditulis dalam Java dan didasarkan pada Apache Lucene. Dirilis pada tahun 2010 dan dengan cepat mendapatkan popularitas karena struktur datanya yang fleksibel, arsitektur yang dapat diskalakan, dan waktu respons yang sangat cepat. Elasticsearch didasarkan pada dokumen JSON dengan struktur bebas skema, membuat adopsi menjadi mudah dan tidak merepotkan. Ini adalah salah satu mesin pencari peringkat teratas kelas perusahaan enterprise. Anda dapat menulis kliennya dalam bahasa pemrograman apa pun; Elasticsearch secara resmi bekerja dengan Java, .NET, PHP, Python, Perl, dan sebagainya.
Elasticsearch terutama berinteraksi menggunakan REST API. Itu mendapat data dalam bentuk dokumen JSON dengan semua parameter yang diperlukan, dan memberikan responsnya dengan cara yang sama.
MongoDB
MongoDB adalah database NoSQL berdasarkan model data penyimpanan dokumen. Di MongoDB semuanya adalah koleksi atau dokumen. Untuk memahami terminologi MongoDB, koleksi adalah kata alternatif untuk tabel, sedangkan dokumen adalah kata alternatif untuk baris.
MongoDB adalah database open source, berorientasi dokumen, dan lintas platform. Hal ini terutama ditulis dalam C++. Ini juga merupakan database NoSQL terkemuka yang memberikan kinerja tinggi, ketersediaan tinggi, dan skalabilitas yang mudah. MongoDB menggunakan dokumen mirip JSON dengan skema dan menyediakan dukungan kueri yang kaya. Beberapa fitur utamanya termasuk pengindeksan, replikasi, penyeimbangan beban, agregasi, dan penyimpanan file.
Cassandra
Cassandra adalah Proyek Apache open source yang dirancang untuk manajemen basis data NoSQL. Baris Cassandra diatur ke dalam tabel dan diindeks oleh kunci. Ini menggunakan mesin penyimpanan berbasis log saja yang ditambahkan. Data di Cassandra didistribusikan di beberapa node masterless, tanpa satu titik kegagalan. Ini adalah proyek Apache tingkat atas, dan pengembangannya saat ini diawasi oleh Apache Software Foundation (ASF).
Cassandra dirancang untuk memecahkan masalah yang terkait dengan pengoperasian pada skala (web) besar. Mengingat arsitektur masterless Cassandra, Cassandra mampu terus melakukan operasi meskipun sejumlah kecil (walaupun signifikan) kegagalan perangkat keras. Cassandra berjalan di beberapa node di beberapa pusat data. Ini mereplikasi data di seluruh pusat data ini untuk menghindari kegagalan atau waktu henti. Ini menjadikannya sistem yang sangat toleran terhadap kesalahan.
Cassandra menggunakan bahasa pemrogramannya sendiri untuk mengakses data di seluruh nodenya. Ini disebut Bahasa Kueri Cassandra atau CQL. Ini mirip dengan SQL, yang terutama digunakan oleh Database Relasional. CQL dapat digunakan dengan menjalankan aplikasinya sendiri yang disebut cqlsh. Cassandra juga menyediakan banyak antarmuka integrasi untuk beberapa bahasa pemrograman untuk membangun aplikasi menggunakan Cassandra. API integrasinya mendukung Java, C++, Python, dan lainnya.
Apache HBase
HBase adalah Proyek Apache lain yang dirancang untuk mengelola penyimpanan data NoSQL. Ini dirancang untuk memanfaatkan fitur Hadoop Ecosystem, termasuk keandalan, toleransi kesalahan, dan sebagainya and. Ini menggunakan HDFS sebagai sistem file untuk tujuan penyimpanan. Ada beberapa model data yang bekerja dengan NoSQL dan Apache HBase termasuk dalam model data berorientasi kolom. HBase awalnya didasarkan pada Google Big Table, yang juga terkait dengan model berorientasi kolom untuk data tidak terstruktur.
HBase menyimpan semuanya dalam bentuk pasangan nilai kunci. Hal penting yang perlu diperhatikan adalah bahwa di HBase, kunci dan nilai dalam bentuk byte. Jadi, untuk menyimpan informasi apa pun di HBase, Anda harus mengubah informasi menjadi byte. (Dengan kata lain, API-nya tidak menerima apa pun selain array byte.) Hati-hati dengan HBase, karena ketika Anda menyimpan data, Anda harus mengingat jenis aslinya. Data yang awalnya berupa string akan kembali sebagai array byte jika dipanggil secara tidak benar. Akibatnya, itu akan membuat bug di aplikasi Anda dan membuat aplikasi Anda crash.
Semoga Anda menikmati artikel ini. Jika Anda ingin merancang dan merancang aplikasi yang intensif data, maka Anda dapat menjelajahi Anuj Kumar's Merancang Aplikasi Data-Intensif. Ini Book adalah gerbang Anda untuk membangun sistem intensif data cerdas dengan menggabungkan prinsip, pola, dan teknik arsitektur inti intensif data langsung ke dalam arsitektur aplikasi Anda.


