Apache Kafka
Untuk definisi tingkat tinggi, izinkan kami menyajikan definisi singkat untuk Apache Kafka:
Apache Kafka adalah log komit yang terdistribusi, toleran terhadap kesalahan, dapat diskalakan secara horizontal.
Itu adalah beberapa kata tingkat tinggi tentang Apache Kafka. Mari kita memahami konsep secara rinci di sini.
- Didistribusikan: Kafka membagi data yang dikandungnya menjadi beberapa server dan masing-masing server ini mampu menangani permintaan dari klien untuk berbagi data yang dikandungnya
- Toleran terhadap kesalahan: Kafka tidak memiliki satu titik Kegagalan. Dalam sistem SPoF, seperti database MySQL, jika server yang menghosting database mati, aplikasinya kacau. Dalam sistem yang tidak memiliki SPoF dan terdiri dari beberapa node, bahkan jika sebagian besar sistem mati, itu masih sama untuk pengguna akhir.
- Dapat diskalakan secara horizontal: Penskalaan semacam ini mengacu pada penambahan lebih banyak mesin ke cluster yang ada. Ini berarti Apache Kafka mampu menerima lebih banyak node di clusternya dan tidak menyediakan waktu henti untuk peningkatan yang diperlukan ke sistem. Perhatikan gambar di bawah ini untuk memahami jenis konsep scaling:
- Komit Log: Log komit adalah Struktur Data seperti Daftar Tertaut. Itu menambahkan pesan apa pun yang datang ke sana dan selalu mempertahankan urutannya. Data tidak dapat dihapus dari log ini sampai waktu yang ditentukan tercapai untuk data tersebut.
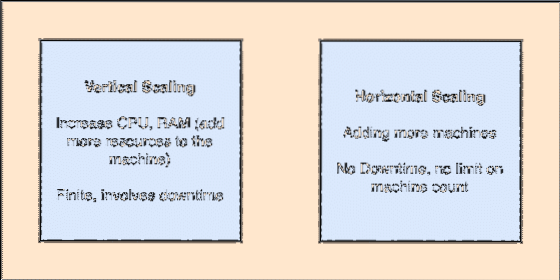
Scaling Vertikal dan Horizontal
Topik di Apache Kafka seperti antrian tempat pesan disimpan. Pesan-pesan ini disimpan untuk waktu yang dapat dikonfigurasi dan pesan tidak akan dihapus sampai waktu ini tercapai, bahkan jika telah dikonsumsi oleh semua konsumen yang dikenal.
Kafka dapat diskalakan karena konsumenlah yang benar-benar menyimpan bahwa pesan apa yang diambil oleh mereka terakhir sebagai nilai 'offset'. Mari kita lihat gambar untuk memahami ini dengan lebih baik: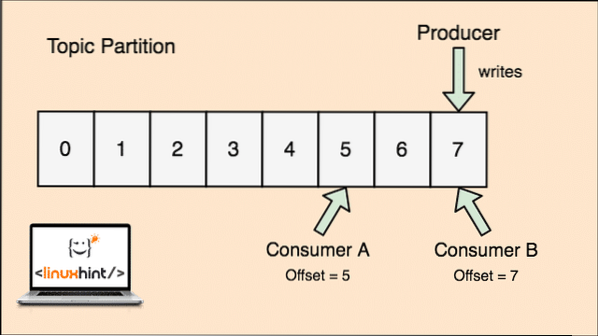
Partisi topik dan offset Konsumen di Apache Kafka
Memulai dengan Apache Kafka
Untuk mulai menggunakan Apache Kafka, itu harus diinstal pada mesin. Untuk melakukan ini, baca Instal Apache Kafka di Ubuntu.
Pastikan Anda memiliki instalasi Kafka yang aktif jika Anda ingin mencoba contoh yang kami sajikan nanti dalam pelajaran.
bagaimana cara kerjanya?
Dengan Kafka, Produsen aplikasi diterbitkan pesan yang tiba di Kafka simpul dan tidak langsung ke Konsumen. Dari Node Kafka ini, pesan dikonsumsi oleh Konsumen aplikasi.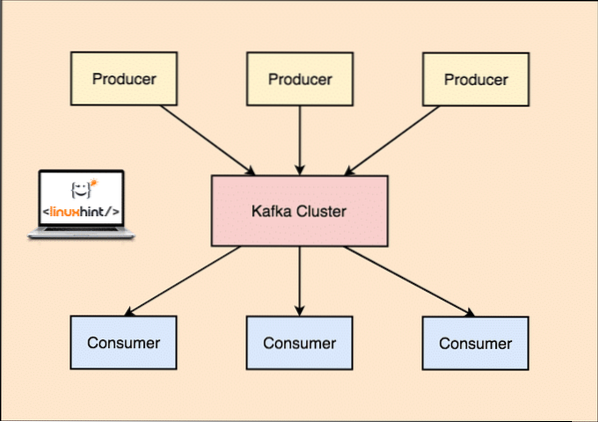
Kafka Produsen dan Konsumen and
Karena satu topik bisa mendapatkan banyak data sekaligus, agar Kafka dapat diskalakan secara horizontal, setiap topik dibagi menjadi partisi dan setiap partisi dapat hidup di mesin node mana pun dari sebuah cluster. Mari kita coba menyajikannya:
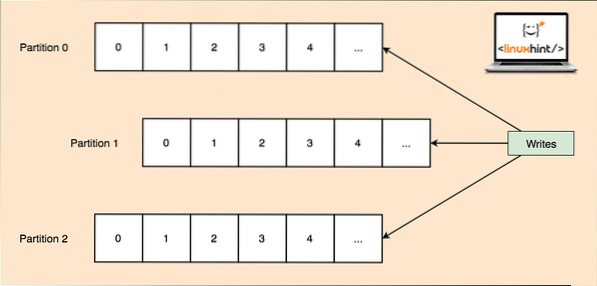
Partisi Topik
Sekali lagi, Kafka Broker tidak mencatat konsumen mana yang telah mengkonsumsi berapa banyak paket data. Ini adalah tanggung jawab konsumen untuk melacak data yang telah dikonsumsi.
Kegigihan ke Disk
Kafka mempertahankan catatan pesan yang didapatnya dari Produser di disk dan tidak menyimpannya di memori. Sebuah pertanyaan yang mungkin muncul adalah bagaimana ini membuat segala sesuatunya menjadi layak dan cepat? Ada beberapa alasan di balik ini yang menjadikannya cara yang optimal untuk mengelola catatan pesan:
- Kafka mengikuti protokol pengelompokan catatan pesan. Produsen menghasilkan pesan yang disimpan ke disk dalam potongan besar dan konsumen mengkonsumsi catatan pesan ini dalam potongan linier besar juga.
- Alasan penulisan disk linier, adalah karena ini membuat pembacaan cepat karena waktu baca disk linier sangat menurun.
- Operasi disk linier dioptimalkan oleh Sistem operasi juga dengan menggunakan teknik menulis di belakang dan baca dulu.
- OS modern juga menggunakan konsep Caching halaman yang berarti mereka men-cache beberapa data disk di RAM yang tersedia Gratis Free.
- Karena Kafka mempertahankan data dalam data standar yang seragam di seluruh aliran dari produsen hingga konsumen, Kafka menggunakan optimasi nol-salin proses.
Distribusi & Replikasi Data
Seperti yang kita pelajari di atas bahwa topik dibagi menjadi beberapa partisi, setiap record pesan direplikasi pada beberapa node cluster untuk menjaga urutan dan data setiap record jika salah satu node mati.
Meskipun sebuah partisi direplikasi pada beberapa node, masih ada pemimpin partisi node di mana aplikasi membaca dan menulis data pada topik dan pemimpin mereplikasi data pada node lain, yang disebut sebagai pengikut dari partisi itu.
Jika data record pesan sangat penting bagi suatu aplikasi, jaminan keamanan record pesan di salah satu node dapat ditingkatkan dengan meningkatkan faktor replikasi dari Cluster.
Apa itu penjaga kebun binatang??
Zookeeper adalah toko nilai kunci terdistribusi yang sangat toleran terhadap kesalahan. Apache Kafka sangat bergantung pada Zookeeper untuk menyimpan mekanisme cluster seperti detak jantung, mendistribusikan pembaruan/konfigurasi, dll).
Ini memungkinkan pialang Kafka untuk berlangganan sendiri dan mengetahui setiap kali ada perubahan mengenai pemimpin partisi dan distribusi node telah terjadi.
Aplikasi Produser dan Konsumen berkomunikasi langsung dengan Zookeeper aplikasi untuk mengetahui node mana yang merupakan pemimpin partisi untuk suatu topik sehingga mereka dapat melakukan membaca dan menulis dari pemimpin partisi.
Streaming
Stream Processor adalah komponen utama dalam klaster Kafka yang mengambil aliran data rekaman pesan secara terus-menerus dari topik input, memproses data ini dan membuat aliran data ke topik keluaran yang dapat berupa apa saja, dari sampah hingga Database.
Sangat mungkin untuk melakukan pemrosesan sederhana secara langsung menggunakan API produsen/konsumen, meskipun untuk pemrosesan kompleks seperti menggabungkan aliran, Kafka menyediakan perpustakaan Streams API terintegrasi tetapi harap dicatat bahwa API ini dimaksudkan untuk digunakan dalam basis kode kita sendiri dan tidak t dijalankan di broker. Ini bekerja mirip dengan API konsumen dan membantu kami meningkatkan pekerjaan pemrosesan aliran di beberapa aplikasi.
Kapan menggunakan Apache Kafka?
Seperti yang kita pelajari di bagian di atas, Apache Kafka dapat digunakan untuk menangani sejumlah besar catatan pesan yang dapat dimiliki oleh topik dalam jumlah yang hampir tak terbatas di sistem kami.
Apache Kafka adalah kandidat ideal dalam hal menggunakan layanan yang memungkinkan kita untuk mengikuti arsitektur yang digerakkan oleh peristiwa dalam aplikasi kita. Hal ini karena kemampuannya dalam persistensi data, toleransi kesalahan, dan arsitektur yang sangat terdistribusi di mana aplikasi penting dapat mengandalkan kinerjanya.
Arsitektur Kafka yang skalabel dan terdistribusi membuat integrasi dengan layanan mikro menjadi sangat mudah dan memungkinkan aplikasi untuk memisahkan dirinya dengan banyak logika bisnis.
Membuat Topik baru
Kita dapat membuat Topik pengujian pengujian di server Apache Kafka dengan perintah berikut:
Membuat Topik
sudo kafka-topik.sh --create --zookeeper localhost:2181 --replication-factor 1--partisi 1 --pengujian topik
Inilah yang kami dapatkan kembali dengan perintah ini: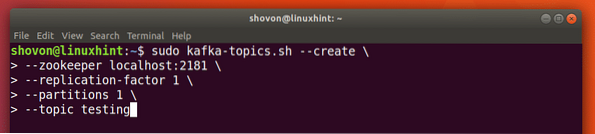
Buat Topik Kafka Baru
Topik pengujian akan dibuat yang dapat kami konfirmasi dengan perintah yang disebutkan:
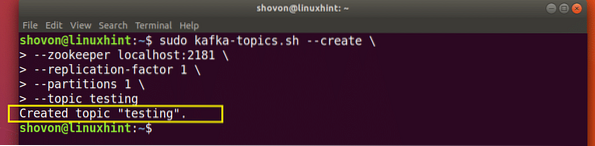
Konfirmasi pembuatan topik Kafka
Menulis Pesan pada Topik
Seperti yang kita pelajari sebelumnya, salah satu API yang ada di Apache Kafka adalah is API Produser. Kami akan menggunakan API ini untuk membuat pesan baru dan mempublikasikan topik yang baru saja kami buat:
Menulis Pesan ke Topik
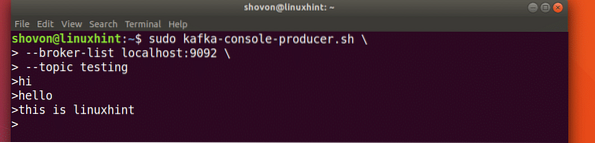
Sudo kafka-konsol-produser.sh --broker-list localhost:9092 --pengujian topikMari kita lihat output untuk perintah ini:
Publikasikan pesan ke Topik Kafka
Setelah kita menekan tombol, kita akan melihat tanda panah baru (>) yang berarti kita bisa keluar data sekarang:

Mengetik pesan
Cukup ketik sesuatu dan tekan untuk memulai baris baru. Saya mengetik 3 baris teks:
Membaca Pesan dari Topik
Sekarang kami telah menerbitkan pesan tentang Topik Kafka yang kami buat, pesan ini akan ada di sana untuk beberapa waktu yang dapat dikonfigurasi. Kita bisa membacanya sekarang menggunakan using API Konsumen:
Membaca Pesan dari Topik
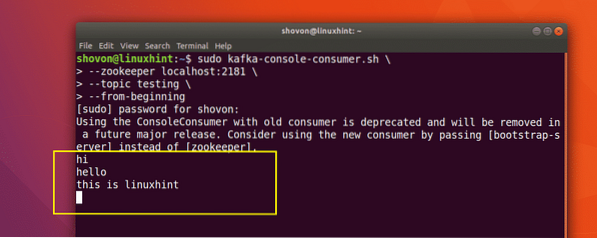
sudo kafka-konsol-konsumen.sh --zookeeper localhost:2181 --pengujian topik --dari awal
Inilah yang kami dapatkan kembali dengan perintah ini:
Perintah untuk membaca Pesan dari Topik Kafka
Kita akan dapat melihat pesan atau baris yang telah kita tulis menggunakan Producer API seperti gambar di bawah ini:
Jika kita menulis pesan baru lainnya menggunakan Producer API, pesan tersebut juga akan langsung ditampilkan di sisi Konsumen:
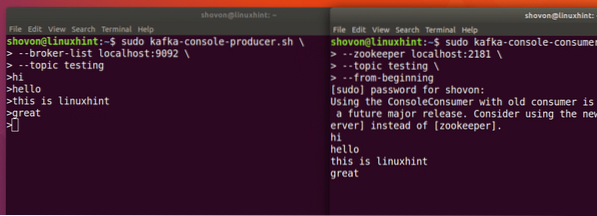
Publikasikan dan Konsumsi secara bersamaan
Kesimpulan
Dalam pelajaran ini, kita melihat bagaimana kita mulai menggunakan Apache Kafka yang merupakan Pialang Pesan yang sangat baik dan juga dapat bertindak sebagai unit persistensi data khusus.


