Bagian 1: Menyiapkan satu simpul
Saat ini, menyimpan dokumen atau data Anda secara elektronik di perangkat penyimpanan menjadi cepat dan mudah, juga relatif murah. Yang digunakan adalah referensi nama file yang dimaksudkan untuk menggambarkan tentang apa dokumen itu. Atau, data disimpan dalam Sistem Manajemen Basis Data (DBMS) seperti PostgreSQL, MariaDB, atau MongoDB untuk menyebutkan beberapa opsi saja. Beberapa media penyimpanan baik yang terhubung secara lokal maupun jarak jauh ke komputer, seperti USB stick, hard disk internal atau eksternal, Network Attached Storage (NAS), Cloud Storage, atau berbasis GPU/Flash, seperti pada Nvidia V100 [10].
Sebaliknya, proses sebaliknya, menemukan dokumen yang tepat dalam kumpulan dokumen, agak rumit. Sebagian besar membutuhkan mendeteksi format file tanpa kesalahan, mengindeks dokumen, dan mengekstraksi konsep kunci (klasifikasi dokumen). Di sinilah kerangka kerja Apache Solr masuk. Ini menawarkan antarmuka praktis untuk melakukan langkah-langkah yang disebutkan - membangun indeks dokumen, menerima permintaan pencarian, melakukan pencarian yang sebenarnya, dan mengembalikan hasil pencarian. Apache Solr dengan demikian membentuk inti untuk penelitian yang efektif pada database atau dokumen silo.
Pada artikel ini, Anda akan mempelajari cara kerja Apache Solr, cara mengatur node tunggal, mengindeks dokumen, melakukan pencarian, dan mengambil hasilnya.
Artikel tindak lanjut dibuat berdasarkan artikel ini, dan, di dalamnya, kami membahas kasus penggunaan lain yang lebih spesifik seperti mengintegrasikan DBMS PostgreSQL sebagai sumber data atau penyeimbangan beban di beberapa node.
Tentang proyek Apache Solr
Apache Solr adalah kerangka kerja mesin pencari berdasarkan server indeks pencarian Lucene yang kuat [2]. Ditulis dalam Java, dikelola di bawah payung Apache Software Foundation (ASF) [6]. Ini tersedia secara bebas di bawah lisensi Apache 2.
Topik "Temukan dokumen dan data lagi" memainkan peran yang sangat penting dalam dunia perangkat lunak, dan banyak pengembang menanganinya secara intensif. Situs web Awesomeopensource [4] mencantumkan lebih dari 150 proyek sumber terbuka mesin pencari. Pada awal 2021, ElasticSearch [8] dan Apache Solr/Lucene adalah dua teratas dalam hal mencari kumpulan data yang lebih besar. Mengembangkan mesin telusur Anda membutuhkan banyak pengetahuan, Frank melakukannya dengan pustaka Advan Pencarian Lanjutan berbasis Python [3] sejak 2002.
Menyiapkan Apache Solr:
Instalasi dan pengoperasian Apache Solr tidak rumit, hanya serangkaian langkah yang harus Anda lakukan. Biarkan sekitar 1 jam untuk hasil kueri data pertama. Selain itu, Apache Solr bukan hanya proyek hobi tetapi juga digunakan dalam lingkungan profesional. Oleh karena itu, lingkungan sistem operasi yang dipilih dirancang untuk penggunaan jangka panjang.
Sebagai lingkungan dasar untuk artikel ini, kami menggunakan Debian GNU/Linux 11, yang merupakan rilis Debian yang akan datang (per awal 2021) dan diharapkan akan tersedia pada pertengahan 2021. Untuk tutorial ini, kami berharap Anda telah menginstalnya, baik sebagai sistem asli, di mesin virtual seperti VirtualBox, atau wadah AWS.
Terlepas dari komponen dasar, Anda memerlukan paket perangkat lunak berikut untuk diinstal pada sistem:
- Keriting
- Default-java
- Libcommons-cli-java
- Libxerces2-java
- Libtika-java (perpustakaan dari proyek Apache Tika [11])
Paket-paket ini adalah komponen standar Debian GNU/Linux. Jika belum terinstal, Anda dapat melakukan pasca-instal sekaligus sebagai pengguna dengan hak administratif, misalnya, root atau melalui sudo, yang ditunjukkan sebagai berikut:
# apt-get install curl default-java libcommons-cli-java libxerces2-java libtika-javaSetelah menyiapkan lingkungan, langkah ke-2 adalah instalasi Apache Solr. Sampai sekarang, Apache Solr tidak tersedia sebagai paket Debian biasa. Oleh karena itu, diperlukan untuk mengambil Apache Solr 8.8 dari bagian unduhan situs web proyek [9] terlebih dahulu. Gunakan perintah wget di bawah ini untuk menyimpannya di direktori /tmp sistem Anda:
$ wget -O /tmp https://downloads.apache.org/lucene/solr/8.8.0/solr-8.8.0.tgzSakelar -O memperpendek -output-document dan membuat wget menyimpan tar yang diambil.file .gz di direktori yang diberikan. Arsip memiliki ukuran sekitar 190M. Selanjutnya, buka paket arsip ke direktori /opt menggunakan tar. Akibatnya, Anda akan menemukan dua subdirektori - /opt/solr dan /opt/solr-8.8.0, sedangkan /opt/solr diatur sebagai tautan simbolis ke yang terakhir. Apache Solr dilengkapi dengan skrip setup yang Anda jalankan selanjutnya, yaitu sebagai berikut:
# /opt/solr-8.8.0/bin/install_solr_service.SHIni menghasilkan pembuatan solr pengguna Linux yang berjalan di layanan Solr ditambah direktori home-nya di bawah /var/solr menetapkan layanan Solr, ditambahkan dengan node yang sesuai, dan memulai layanan Solr pada port 8983. Ini adalah nilai default. Jika Anda tidak puas dengannya, Anda dapat memodifikasinya selama instalasi atau bahkan nanti karena skrip instalasi menerima sakelar yang sesuai untuk penyesuaian pengaturan. Kami menyarankan Anda untuk melihat dokumentasi Apache Solr mengenai parameter ini.
Perangkat lunak Solr diatur dalam direktori berikut:
- tempat sampah
berisi binari dan file Solr untuk menjalankan Solr sebagai layanan - berkontribusi
perpustakaan Solr eksternal seperti pengendali impor data dan perpustakaan Lucene - jarak
perpustakaan Solr internal - dokumen
tautan ke dokumentasi Solr yang tersedia online - contoh
contoh kumpulan data atau beberapa kasus/skenario penggunaan - lisensi
lisensi perangkat lunak untuk berbagai komponen Solr - server
file konfigurasi server, seperti server/dll untuk layanan dan port
Lebih detail, Anda dapat membaca tentang direktori ini di dokumentasi Apache Solr [12].
Mengelola Apache Solr:
Apache Solr berjalan sebagai layanan di latar belakang. Anda dapat memulainya dengan dua cara, baik menggunakan systemctl (baris pertama) sebagai pengguna dengan izin administratif atau langsung dari direktori Solr (baris kedua). Kami mencantumkan kedua perintah terminal di bawah ini:
# systemctl start solr$ solr/bin/solr mulai
Menghentikan Apache Solr dilakukan dengan cara yang sama:
# systemctl stop solr$ solr/bin/solr berhenti
Cara yang sama berlaku dalam me-restart layanan Apache Solr:
# systemctl restart solr$solr/bin/solr restart
Selanjutnya status proses Apache Solr dapat ditampilkan sebagai berikut:
# sistemctl status solr$solr/bin/solr status
Output mencantumkan file layanan yang dimulai, baik stempel waktu dan pesan log yang sesuai. Gambar di bawah ini menunjukkan bahwa layanan Apache Solr dimulai pada port 8983 dengan proses 632. Proses berhasil berjalan selama 38 menit.
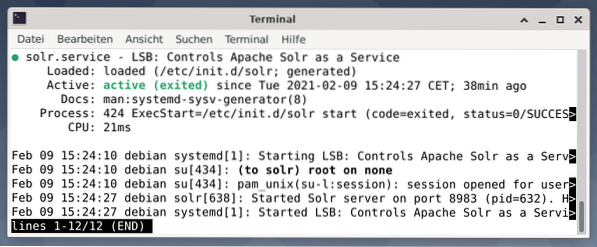
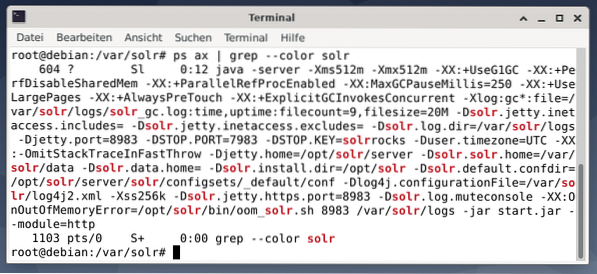
Untuk melihat apakah proses Apache Solr aktif, Anda juga dapat memeriksa silang menggunakan perintah ps yang dikombinasikan dengan grep. Ini membatasi output ps ke semua proses Apache Solr yang saat ini aktif.
# ps kapak | grep --warna solrGambar di bawah menunjukkan ini untuk satu proses. Anda melihat panggilan Java yang disertai dengan daftar parameter, misalnya penggunaan memori (512M) port untuk mendengarkan 8983 untuk kueri, 7983 untuk permintaan berhenti, dan jenis koneksi (http).
Menambahkan pengguna:
Proses Apache Solr dijalankan dengan pengguna tertentu bernama solr. Pengguna ini sangat membantu dalam mengelola proses Solr, mengunggah data, dan mengirim permintaan. Setelah penyiapan, solr pengguna tidak memiliki kata sandi dan diharapkan memiliki kata sandi untuk masuk untuk melangkah lebih jauh. Tetapkan kata sandi untuk pengguna solr seperti root pengguna, itu ditunjukkan sebagai berikut:
#passwd solrAdministrasi Solr:
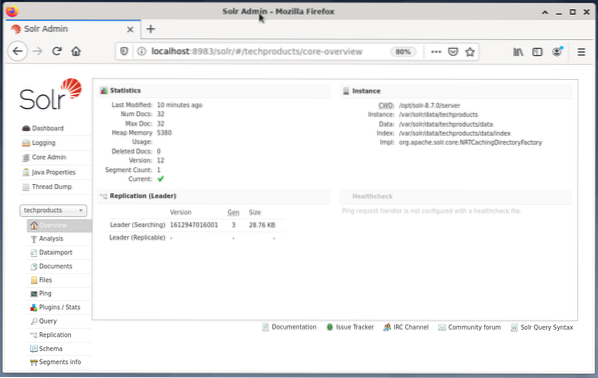
Mengelola Apache Solr dilakukan menggunakan Dasbor Solr. Ini dapat diakses melalui browser web dari http://localhost:8983/solr. Gambar di bawah ini menunjukkan tampilan utama.
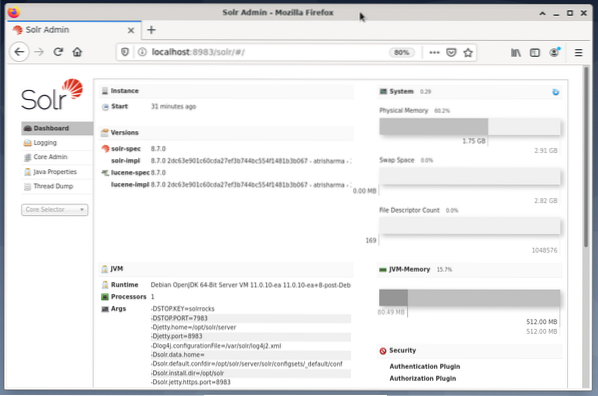
Di sebelah kiri, Anda melihat menu utama yang mengarahkan Anda ke subbagian untuk pencatatan, administrasi inti Solr, pengaturan Java, dan informasi status. Pilih inti yang diinginkan menggunakan kotak pilihan di bawah menu. Di sisi kanan menu, informasi terkait ditampilkan. Entri menu Dasbor menunjukkan detail lebih lanjut mengenai proses Apache Solr, serta penggunaan beban dan memori saat ini.
Perlu diketahui bahwa isi Dashboard berubah tergantung jumlah Solr core, dan dokumen yang telah terindeks. Perubahan memengaruhi item menu dan informasi terkait yang terlihat di sebelah kanan.
Memahami Cara Kerja Mesin Pencari:
Sederhananya, mesin pencari menganalisis dokumen, mengkategorikannya, dan memungkinkan Anda melakukan pencarian berdasarkan kategorisasinya. Pada dasarnya proses tersebut terdiri dari tiga tahap, yang disebut sebagai crawling, indexing, dan ranking [13].
Merangkak adalah tahap pertama dan menjelaskan proses pengumpulan konten baru dan yang diperbarui. Mesin pencari menggunakan robot yang juga dikenal sebagai spider atau crawler, maka istilah crawling untuk menelusuri dokumen yang tersedia.
Tahap kedua disebut pengindeksan. Konten yang dikumpulkan sebelumnya dibuat dapat dicari dengan mengubah dokumen asli ke dalam format yang dimengerti oleh mesin pencari. Kata kunci dan konsep diekstraksi dan disimpan dalam basis data (besar).
Tahap ketiga disebut peringkat dan menjelaskan proses pengurutan hasil penelusuran menurut relevansinya dengan kueri penelusuran. Adalah umum untuk menampilkan hasil dalam urutan menurun sehingga hasil yang memiliki relevansi tertinggi dengan kueri pencari didahulukan.
Apache Solr bekerja mirip dengan proses tiga tahap yang dijelaskan sebelumnya. Seperti mesin pencari populer Google, Apache Solr menggunakan urutan pengumpulan, penyimpanan, dan pengindeksan dokumen dari berbagai sumber dan membuatnya tersedia/dapat dicari hampir secara real-time.
Apache Solr menggunakan berbagai cara untuk mengindeks dokumen termasuk yang berikut [14]:
- Menggunakan Handler Permintaan Indeks saat mengunggah dokumen langsung ke Solr. Dokumen-dokumen ini harus dalam format JSON, XML/XSLT, atau CSV.
- Menggunakan Handler Permintaan Ekstraksi (Solr Cell). Dokumen harus dalam format PDF atau Office, yang didukung oleh Apache Tika.
- Menggunakan Data Import Handler, yang menyampaikan data dari database dan mengkatalogkannya menggunakan nama kolom. Data Import Handler mengambil data dari email, RSS feed, data XML, database, dan file teks biasa sebagai sumber.
Penangan kueri digunakan di Apache Solr saat permintaan pencarian dikirim. Penangan kueri menganalisis kueri yang diberikan berdasarkan konsep yang sama dari pengendali indeks untuk mencocokkan kueri dan dokumen yang diindeks sebelumnya. Pertandingan diberi peringkat sesuai dengan kesesuaian atau relevansinya. Contoh singkat dari query ditunjukkan di bawah ini.
Mengunggah Dokumen:
Demi kesederhanaan, kami menggunakan contoh dataset untuk contoh berikut yang sudah disediakan oleh Apache Solr. Mengunggah dokumen dilakukan sebagai pengguna solr. Langkah 1 adalah pembuatan inti dengan nama produk teknologi (untuk sejumlah item teknologi).
$ solr/bin/solr create -c techproducts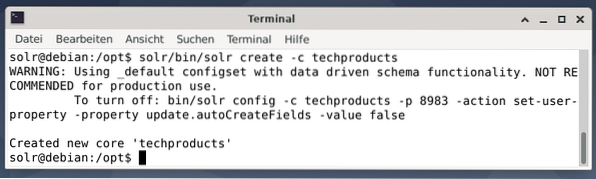
Semuanya baik-baik saja jika Anda melihat pesan “Created new core 'techproducts'”. Langkah 2 adalah menambahkan data (data XML dari exampledocs) ke produk teknologi inti yang dibuat sebelumnya. Yang digunakan adalah posting alat yang diparameterisasi oleh -c (nama inti) dan dokumen yang akan diunggah.
$ solr/bin/post -c techproducts solr/example/exampledocs/*.xmlIni akan menghasilkan output yang ditunjukkan di bawah ini dan akan berisi seluruh panggilan ditambah 14 dokumen yang telah diindeks.
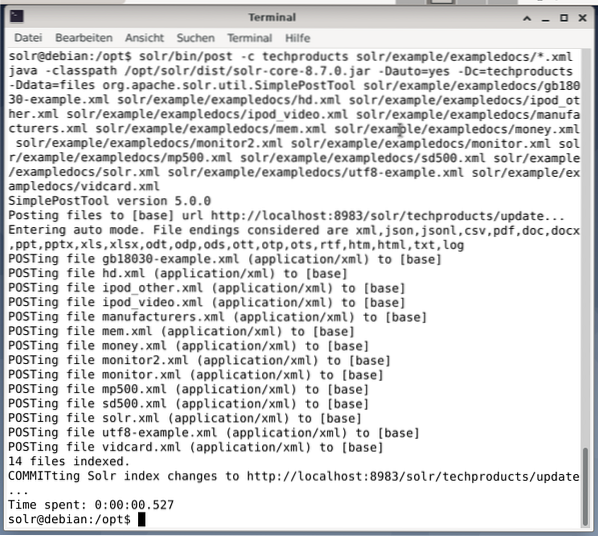
Juga, Dasbor menunjukkan perubahan. Entri baru bernama techproducts terlihat di menu tarik-turun di sisi kiri, dan jumlah dokumen terkait diubah di sisi kanan. Sayangnya, tampilan mendetail dari kumpulan data mentah tidak dimungkinkan.
Jika inti/koleksi perlu dihapus, gunakan perintah berikut:
$ solr/bin/solr hapus -c techproductsMeminta Data:
Apache Solr menawarkan dua antarmuka untuk meminta data: melalui Dasbor berbasis web dan baris perintah. Kami akan menjelaskan kedua metode di bawah ini.
Mengirim kueri melalui dasbor Solr dilakukan sebagai berikut:
- Pilih produk teknologi simpul dari menu tarik-turun.
- Pilih entri Query dari menu di bawah menu dropdown.
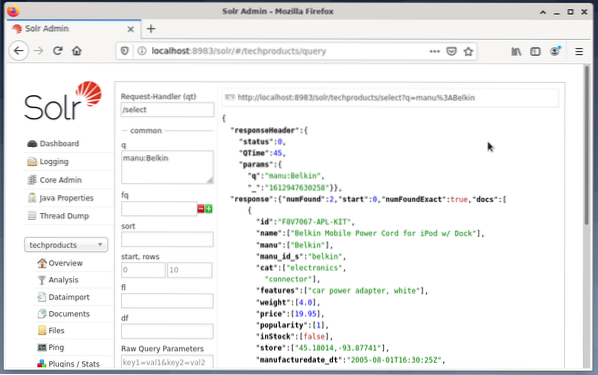
Bidang entri muncul di sisi kanan untuk merumuskan kueri seperti pengendali permintaan (qt), kueri (q), dan urutan pengurutan (sort). - Pilih kolom entri Query, dan ubah isi entri dari “*:*” menjadi “manu:Belkin”. Ini membatasi pencarian dari "semua bidang dengan semua entri" ke "set data yang memiliki nama Belkin di bidang manu". Dalam hal ini, nama manu menyingkat produsen dalam kumpulan data contoh.
- Selanjutnya, tekan tombol dengan Execute Query. Hasilnya adalah permintaan HTTP tercetak di atas, dan hasil dari permintaan pencarian dalam format data JSON di bawah ini.
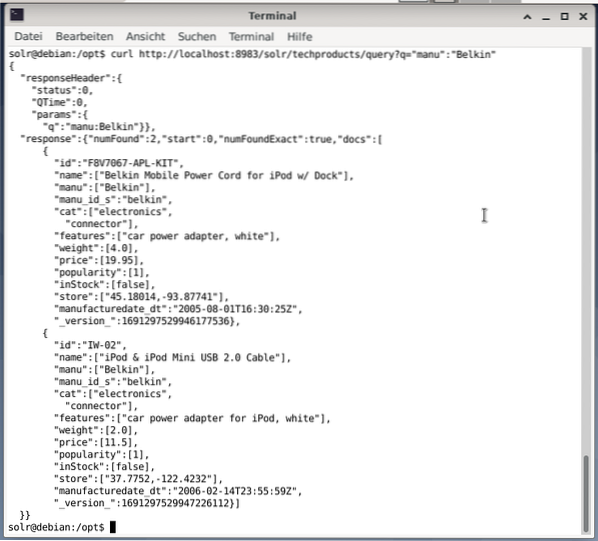
Baris perintah menerima kueri yang sama seperti di Dasbor. Perbedaannya adalah Anda harus mengetahui nama bidang kueri. Untuk mengirim kueri yang sama seperti di atas, Anda harus menjalankan perintah berikut di terminal:
$ ikalhttp://localhost:8983/solr/techproducts/query?q="manu":"Belkin
Outputnya dalam format JSON, seperti yang ditunjukkan di bawah ini. Hasilnya terdiri dari header respons dan respons aktual. Respons terdiri dari dua set data data.
Membungkus:
Selamat! Anda telah mencapai tahap pertama dengan sukses. Infrastruktur dasar telah disiapkan, dan Anda telah mempelajari cara mengunggah dan menanyakan dokumen.
Langkah selanjutnya akan mencakup cara memperbaiki kueri, merumuskan kueri yang lebih kompleks, dan memahami berbagai formulir web yang disediakan oleh halaman kueri Apache Solr. Selain itu, kita akan membahas bagaimana mem-posting hasil pencarian menggunakan format output yang berbeda seperti XML, CSV, dan JSON.
Tentang Penulis:
Jacqui Kabeta adalah seorang pencinta lingkungan, peneliti, pelatih, dan mentor. Di beberapa negara Afrika, ia telah bekerja di industri TI dan lingkungan LSM.
Frank Hofmann adalah pengembang, pelatih, dan penulis TI dan lebih suka bekerja dari Berlin, Jenewa, dan Cape Town. Rekan penulis Buku Manajemen Paket Debian tersedia dari dpmb.organisasi
- [1] Apache Solr, https://lucene.apache.org/solr/
- [2] Perpustakaan Pencarian Lucene, https://lucene.apache.organisasi/
- [3] Pencarian Lanjutan AdvaS, https://pypi.org/project/AdvaS-Advanced-Search/
- [4] 165 Proyek Sumber Terbuka Mesin Pencari Teratas, https://awesomeopensource.com/projects/mesin telusur
- [5] ElasticSearch, https://www.elastis.co/de/elasticsearch/
- [6]Apache Software Foundation (ASF), https://www.apache.organisasi/
- [7]FESS, https://fess.codelib.org/indeks.html
- [8] ElasticSearch, https://www.elastis.kode/
- [9] Apache Solr, bagian Unduh, https://lucene.apache.org/solr/download.htm
- [10] Nvidia V100, https://www.nvidia.com/en-us/pusat data/v100/
- [11] Apache Tika, https://tika.apache.organisasi/
- [12] Tata letak direktori Apache Solr, https://lucene.apache.org/solr/guide/8_8/installing-solr.html#direktori-tata letak
- [13] Cara Kerja Mesin Pencari: Perayapan, Pengindeksan, dan Pemeringkatan. Panduan pemula untuk SEO https://moz.com/beginners-guide-to-seo/how-search-engines-operate
- [14] Memulai Apache Solr, https://sematext.com/guides/solr/#:~:text=Solr%20works%20by%20gathering%2C%20menyimpan, dengan%20huge%20volumes%20of%20data


