Pada artikel ini, kita akan membahas penggunaan dasar grup berdasarkan fungsi di python panda. Semua perintah dijalankan di editor Pycharm.
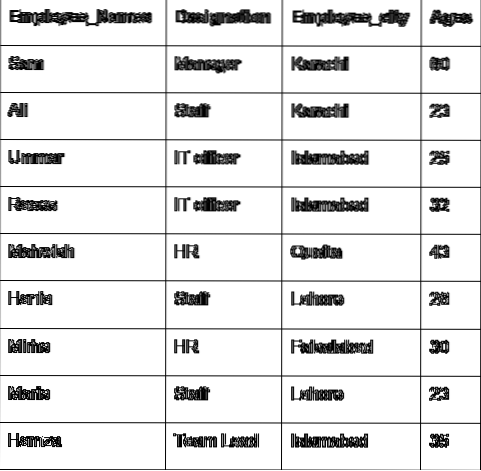
Mari kita bahas konsep utama grup dengan bantuan data karyawan. Kami telah membuat kerangka data dengan beberapa detail karyawan yang berguna (Nama_Karyawan, Penunjukan, Kota_Karyawan, Usia).
Penggabungan String menggunakan Group by Function
Menggunakan fungsi groupby, Anda dapat menggabungkan string. Catatan yang sama dapat digabungkan dengan ',' dalam satu sel.
Contoh
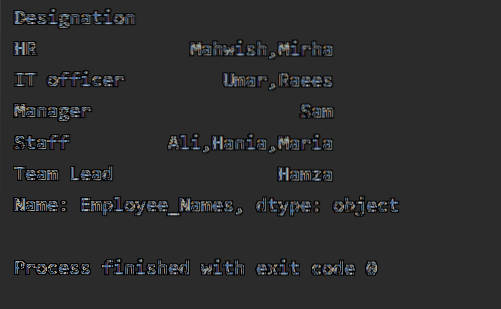
Pada contoh berikut, kami telah mengurutkan data berdasarkan kolom 'Penunjukan' karyawan dan bergabung dengan Karyawan yang memiliki sebutan yang sama. Fungsi lambda diterapkan pada 'Employees_Name'.
impor panda sebagai pddf = pd.Bingkai Data(
'Nama_Karyawan':['Sam', 'Ali' , 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Penunjukan':['Manajer', 'Staf', 'Petugas TI', 'Petugas TI', 'SDM', 'Staf', 'SDM', 'Staf', 'Pemimpin Tim'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Usia_Karyawan':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1=df.groupby("Penunjukan")['Nama_Karyawan'].apply(nama_karyawan lambda: ','.bergabung(Nama_Karyawan))
cetak(df1)
Ketika kode di atas dijalankan, output berikut akan ditampilkan:
Mengurutkan Nilai dalam urutan menaik
Gunakan objek groupby ke dalam kerangka data biasa dengan memanggil '.to_frame()' dan kemudian gunakan reset_index() untuk mengindeks ulang. Urutkan nilai kolom dengan memanggil sort_values().
Contoh
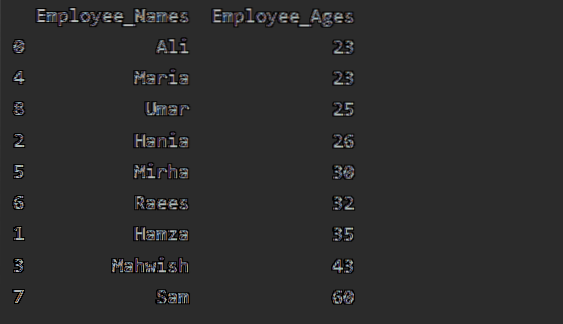
Dalam contoh ini, kami akan mengurutkan usia Karyawan dalam urutan menaik. Menggunakan potongan kode berikut, kami telah mengambil 'Employee_Age' dalam urutan menaik dengan 'Employee_Names'.
impor panda sebagai pddf = pd.Bingkai Data(
'Nama_Karyawan':['Sam', 'Ali' , 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Penunjukan':['Manajer', 'Staf', 'Petugas TI', 'Petugas TI', 'SDM', 'Staf', 'SDM', 'Staf', 'Pemimpin Tim'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Usia_Karyawan':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1=df.groupby('Nama_Karyawan')['Umur_Karyawan'].jumlah().untuk membingkai().reset_indeks().sort_values(berdasarkan='Employee_Umur')
cetak(df1)
Penggunaan agregat dengan groupby
Ada sejumlah fungsi atau agregasi yang tersedia yang dapat Anda terapkan pada grup data seperti count(), sum(), mean(), median(), mode(), std(), min(), max().
Contoh
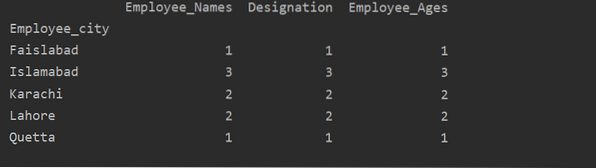
Dalam contoh ini, kami telah menggunakan fungsi 'count()' dengan groupby untuk menghitung Karyawan yang termasuk dalam 'Employee_city' yang sama.
impor panda sebagai pddf = pd.Bingkai Data(
'Nama_Karyawan':['Sam', 'Ali' , 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Penunjukan':['Manajer', 'Staf', 'Petugas TI', 'Petugas TI', 'SDM', 'Staf', 'SDM', 'Staf', 'Pemimpin Tim'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Usia_Karyawan':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1=df.groupby('Karyawan_kota').menghitung()
cetak(df1)
Seperti yang dapat Anda lihat pada output berikut, di bawah kolom Designation, Employee_Names, dan Employee_Age, hitung angka yang berasal dari kota yang sama:
Visualisasikan data menggunakan groupby
Dengan menggunakan 'impor matplotlib.pyplot', Anda dapat memvisualisasikan data Anda ke dalam grafik.
Contoh
Di sini, contoh berikut memvisualisasikan 'Employee_Age' dengan 'Employee_Nmaes' dari DataFrame yang diberikan dengan menggunakan pernyataan groupby.
impor panda sebagai pdimpor matplotlib.pyplot sebagai plt
kerangka data = pd.Bingkai Data(
'Nama_Karyawan':['Sam', 'Ali' , 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Penunjukan':['Manajer', 'Staf', 'Petugas TI', 'Petugas TI', 'SDM', 'Staf', 'SDM', 'Staf', 'Pemimpin Tim'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Usia_Karyawan':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
plt.clf()
kerangka data.groupby('Nama_Karyawan').jumlah().plot (jenis = 'bar')
plt.menunjukkan()
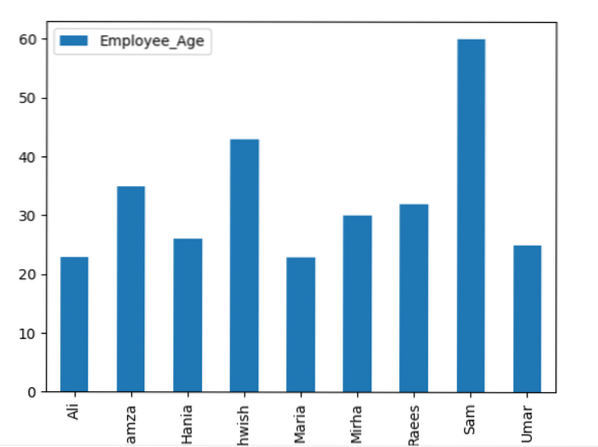
Contoh
Untuk memplot grafik bertumpuk menggunakan groupby, putar 'stacked=true' dan gunakan kode berikut:
impor panda sebagai pdimpor matplotlib.pyplot sebagai plt
df = pd.Bingkai Data(
'Nama_Karyawan':['Sam', 'Ali' , 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Penunjukan':['Manajer', 'Staf', 'Petugas TI', 'Petugas TI', 'SDM', 'Staf', 'SDM', 'Staf', 'Pemimpin Tim'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Usia_Karyawan':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df.groupby(['Karyawan_kota','Nama_Karyawan']).ukuran().membongkar().plot(kind='bar',stacked=True, fontsize='6')
plt.menunjukkan()
Dalam grafik yang diberikan di bawah ini, jumlah karyawan yang ditumpuk yang berasal dari kota yang sama.
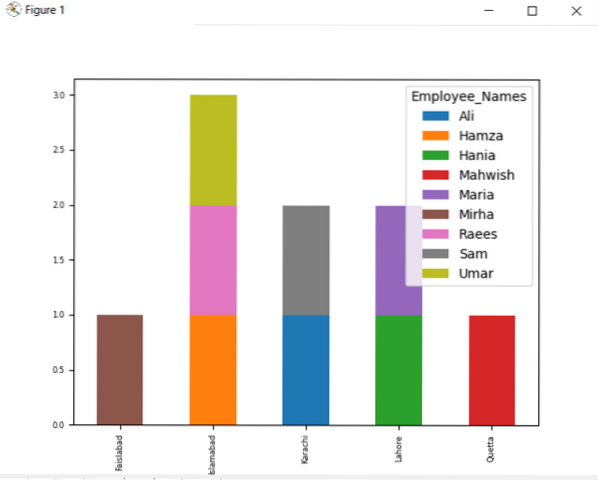
Ubah Nama Kolom dengan grup dengan
Anda juga dapat mengubah nama kolom teragregasi dengan beberapa nama baru yang dimodifikasi sebagai berikut:
impor panda sebagai pdimpor matplotlib.pyplot sebagai plt
df = pd.Bingkai Data(
'Nama_Karyawan':['Sam', 'Ali' , 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Penunjukan':['Manajer', 'Staf', 'Petugas TI', 'Petugas TI', 'SDM', 'Staf', 'SDM', 'Staf', 'Pemimpin Tim'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Usia_Karyawan':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby('Nama_Karyawan')['Penunjukan'].jumlah().reset_index(name='Employee_Designation')
cetak(df1)
Dalam contoh di atas, nama 'Penunjukan' diubah menjadi 'Penunjukan_Karyawan'.
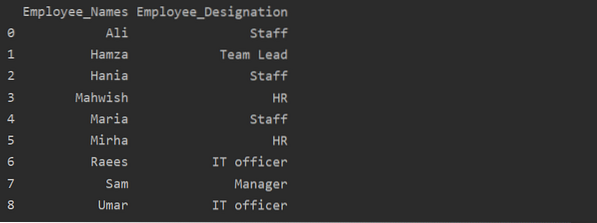
Ambil Grup berdasarkan kunci atau nilai
Menggunakan pernyataan groupby, Anda dapat mengambil catatan atau nilai serupa dari kerangka data.
Contoh
Dalam contoh yang diberikan di bawah ini, kami memiliki data grup berdasarkan 'Penunjukan'. Kemudian, grup 'Staf' diambil dengan menggunakan .getgroup('Staf').
impor panda sebagai pdimpor matplotlib.pyplot sebagai plt
df = pd.Bingkai Data(
'Nama_Karyawan':['Sam', 'Ali' , 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Penunjukan':['Manajer', 'Staf', 'Petugas TI', 'Petugas TI', 'SDM', 'Staf', 'SDM', 'Staf', 'Pemimpin Tim'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Usia_Karyawan':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
ekstrak_nilai = df.groupby('Penunjukan')
cetak(nilai_ekstrak.get_group('Staf'))
Hasil berikut ditampilkan di jendela output:

Tambahkan Nilai ke dalam Daftar grup
Data serupa dapat ditampilkan dalam bentuk daftar dengan menggunakan pernyataan groupby. Pertama, kelompokkan data berdasarkan kondisi. Kemudian, dengan menerapkan fungsi tersebut, Anda dapat dengan mudah memasukkan grup ini ke dalam daftar.
Contoh
Dalam contoh ini, kami telah memasukkan catatan serupa ke dalam daftar grup. Semua karyawan dibagi ke dalam grup berdasarkan 'Employee_city', dan kemudian dengan menerapkan fungsi 'Lambda', grup ini diambil dalam bentuk daftar.
impor panda sebagai pddf = pd.Bingkai Data(
'Nama_Karyawan':['Sam', 'Ali' , 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Penunjukan':['Manajer', 'Staf', 'Petugas TI', 'Petugas TI', 'SDM', 'Staf', 'SDM', 'Staf', 'Pemimpin Tim'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Usia_Karyawan':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1=df.groupby('Karyawan_kota')['Nama_Karyawan'].terapkan (lambda group_series: group_series.daftar()).reset_indeks()
cetak(df1)
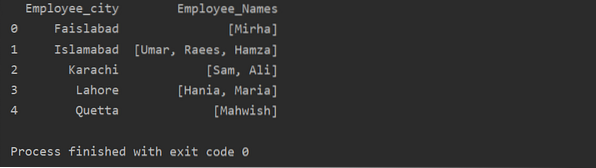
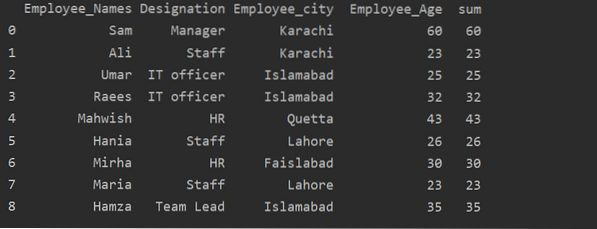
Penggunaan fungsi Transform dengan groupby
Karyawan dikelompokkan menurut usia mereka, nilai-nilai ini ditambahkan bersama-sama, dan dengan menggunakan fungsi 'transformasi' kolom baru ditambahkan dalam tabel:
impor panda sebagai pddf = pd.Bingkai Data(
'Nama_Karyawan':['Sam', 'Ali' , 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Penunjukan':['Manajer', 'Staf', 'Petugas TI', 'Petugas TI', 'SDM', 'Staf', 'SDM', 'Staf', 'Pemimpin Tim'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Usia_Karyawan':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df['jumlah']=df.groupby(['Nama_Karyawan'])['Umur_Karyawan'].transformasi('jumlah')
cetak (df)
Kesimpulan
Kami telah menjelajahi berbagai penggunaan pernyataan groupby dalam artikel ini. Kami telah menunjukkan bagaimana Anda dapat membagi data ke dalam grup, dan dengan menerapkan agregasi atau fungsi yang berbeda, Anda dapat dengan mudah mengambil grup ini.


