Dalam pelajaran tentang Machine Learning dengan scikit-learn ini, kita akan mempelajari berbagai aspek dari paket Python yang luar biasa ini yang memungkinkan kita untuk menerapkan kemampuan Machine Learning yang sederhana dan kompleks pada kumpulan data yang beragam bersama dengan fungsionalitas untuk menguji hipotesis yang kita buat.
Paket scikit-learn berisi alat sederhana dan efisien untuk menerapkan penambangan data dan analisis data pada kumpulan data dan algoritme ini tersedia untuk diterapkan dalam konteks yang berbeda. Ini adalah paket sumber terbuka yang tersedia di bawah lisensi BSD, yang berarti bahwa kita dapat menggunakan perpustakaan ini bahkan secara komersial. Itu dibangun di atas matplotlib, NumPy dan SciPy sehingga sifatnya serbaguna versatile. Kami akan menggunakan Anaconda dengan notebook Jupyter untuk menyajikan contoh dalam pelajaran ini.
Apa yang disediakan scikit-learn?
Pustaka scikit-learn berfokus sepenuhnya pada pemodelan data. Harap dicatat bahwa tidak ada fungsi utama yang ada di scikit-learn saat memuat, memanipulasi, dan meringkas data. Berikut adalah beberapa model populer yang disediakan scikit-learn kepada kami:
- Kekelompokan untuk mengelompokkan data berlabel
- Kumpulan data untuk menyediakan kumpulan data uji dan menyelidiki perilaku model
- Validasi silang untuk memperkirakan kinerja model yang diawasi pada data yang tidak terlihat
- Metode ansambel untuk menggabungkan prediksi beberapa model yang diawasi
- Ekstraksi fitur untuk mendefinisikan atribut dalam data gambar dan teks
Instal Python scikit-belajar
Sekedar catatan sebelum memulai proses instalasi, kami menggunakan lingkungan virtual untuk pelajaran ini yang kami buat dengan perintah berikut:
python -m virtualenv scikitsumber scikit/bin/aktifkan
Setelah lingkungan virtual aktif, kita dapat menginstal perpustakaan pandas di dalam virtual env sehingga contoh yang kita buat selanjutnya dapat dieksekusi:
pip install scikit-belajarAtau, kita dapat menggunakan Conda untuk menginstal paket ini dengan perintah berikut:
conda install scikit-belajarKami melihat sesuatu seperti ini ketika kami menjalankan perintah di atas:

Setelah penginstalan selesai dengan Conda, kami akan dapat menggunakan paket dalam skrip Python kami sebagai:
impor sklearnMari mulai menggunakan scikit-learn dalam skrip kami untuk mengembangkan algoritme Pembelajaran Mesin yang mengagumkan.
Mengimpor Kumpulan Data
Salah satu hal keren dengan scikit-learn adalah ia telah dimuat sebelumnya dengan kumpulan data sampel yang dengannya mudah untuk memulai dengan cepat. Dataset adalah iris dan angka kumpulan data untuk klasifikasi dan harga rumah boston kumpulan data untuk teknik regresi. Di bagian ini, kita akan melihat cara memuat dan mulai menggunakan set data iris.
Untuk mengimpor kumpulan data, pertama-tama kita harus mengimpor modul yang benar diikuti dengan menahan kumpulan data:
dari set data impor sklearniris = kumpulan data.beban_iris()
digit = kumpulan data.beban_digit()
angka.data
Setelah kita menjalankan potongan kode di atas, kita akan melihat output berikut:

Semua output dihapus untuk singkatnya. Ini adalah kumpulan data yang sebagian besar akan kita gunakan dalam pelajaran ini, tetapi sebagian besar konsep dapat diterapkan pada semua kumpulan data secara umum.
Fakta yang menyenangkan untuk mengetahui bahwa ada beberapa modul yang ada di scikit ekosistem, salah satunya adalah belajar digunakan untuk algoritma Machine Learning. Lihat halaman ini untuk banyak modul lain yang hadir.
Menjelajahi Kumpulan Data
Sekarang kita telah mengimpor kumpulan data digit yang disediakan ke dalam skrip kita, kita harus mulai mengumpulkan informasi dasar tentang kumpulan data dan itulah yang akan kita lakukan di sini. Berikut adalah hal-hal dasar yang harus Anda jelajahi saat mencari informasi tentang kumpulan data:
- Nilai atau label target
- Atribut deskripsi
- Kunci yang tersedia dalam kumpulan data yang diberikan
Mari kita menulis potongan kode pendek untuk mengekstrak tiga informasi di atas dari dataset kita:
print('Target: ', digit.target)print('Tombol: ', digit.kunci())
print('Deskripsi: ', angka.DESKR)
Setelah kita menjalankan potongan kode di atas, kita akan melihat output berikut:
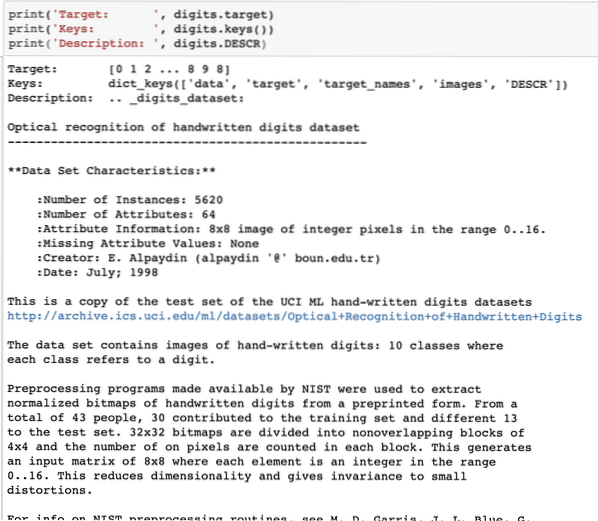
Harap dicatat bahwa angka variabel tidak langsung. Ketika kami mencetak dataset digit, itu sebenarnya berisi array numpy. Kita akan melihat bagaimana kita dapat mengakses array ini. Untuk ini, perhatikan kunci yang tersedia dalam contoh digit yang kami cetak di cuplikan kode terakhir.
Kita akan mulai dengan mendapatkan bentuk data array, yaitu baris dan kolom yang dimiliki array array. Untuk ini, pertama-tama kita perlu mendapatkan data aktual dan kemudian mendapatkan bentuknya:
digit_set = digit.datacetak(digit_set.bentuk)
Setelah kita menjalankan potongan kode di atas, kita akan melihat output berikut:

Ini berarti bahwa kami memiliki 1797 sampel yang ada dalam kumpulan data kami bersama dengan 64 fitur data (atau kolom). Selain itu, kami juga memiliki beberapa label target yang akan kami visualisasikan di sini dengan bantuan matplotlib. Berikut adalah cuplikan kode yang membantu kami melakukannya:
impor matplotlib.pyplot sebagai plt# Gabungkan gambar dan label target sebagai daftar
images_and_labels = daftar(zip(digit.gambar, angka.target))
untuk indeks, (gambar, label) di enumerate(images_and_labels[:8]):
# inisialisasi subplot 2X4 pada posisi ke-i+1
plt.subplot(2, 4, indeks + 1)
# Tidak perlu memplot sumbu apa pun
plt.sumbu('mati')
# Tampilkan gambar di semua subplot
plt.imshow(gambar, cmap=plt.cm.grey_r,interpolasi='terdekat')
# Tambahkan judul ke setiap subplot
plt.title('Pelatihan: ' + str(label))
plt.menunjukkan()
Setelah kita menjalankan potongan kode di atas, kita akan melihat output berikut:

Perhatikan bagaimana kami menyatukan dua array NumPy sebelum memplotnya ke dalam kisi 4 kali 2 tanpa informasi sumbu apa pun. Sekarang, kami yakin tentang informasi yang kami miliki tentang kumpulan data yang kami kerjakan.
Sekarang kami tahu bahwa kami memiliki 64 fitur data (yang merupakan banyak fitur), sulit untuk memvisualisasikan data aktual. Kami punya solusi untuk ini.
Analisis Komponen Utama (PCA)
Ini bukan tutorial tentang PCA, tapi mari kita berikan sedikit gambaran tentang apa itu PCA. Seperti yang kita ketahui bahwa untuk mengurangi jumlah fitur dari kumpulan data, kita memiliki dua teknik:
- Penghapusan Fitur
- Ekstraksi Fitur
Sementara teknik pertama menghadapi masalah fitur data yang hilang bahkan ketika itu mungkin penting, teknik kedua tidak mengalami masalah karena dengan bantuan PCA, kami membangun fitur data baru (jumlahnya lebih sedikit) di mana kami menggabungkan memasukkan variabel sedemikian rupa, sehingga kita dapat mengabaikan variabel "paling tidak penting" sambil tetap mempertahankan bagian paling berharga dari semua variabel.
Seperti yang diantisipasi, PCA membantu kami mengurangi dimensi data yang tinggi yang merupakan hasil langsung dari mendeskripsikan suatu objek menggunakan banyak fitur data. Tidak hanya angka, tetapi banyak kumpulan data praktis lainnya memiliki banyak fitur yang mencakup data institusi keuangan, data cuaca dan ekonomi untuk suatu wilayah, dll. Saat kami melakukan PCA pada kumpulan data digit, tujuan kami adalah menemukan hanya 2 fitur sehingga mereka memiliki sebagian besar karakteristik dari kumpulan data.
Mari kita tulis cuplikan kode sederhana untuk menerapkan PCA pada kumpulan data digit untuk mendapatkan model linier hanya dengan 2 fitur:
dari sklearn.dekomposisi impor PCAfeature_pca = PCA(n_components=2)
reduksi_data_random = fitur_pca.fit_transform(digit.data)
model_pca = PCA(n_komponen=2)
pengurangan_data_pca = model_pca.fit_transform(digit.data)
dikurangi_data_pca.bentuk
cetak(reduced_data_random)
cetak(reduced_data_pca)
Setelah kita menjalankan potongan kode di atas, kita akan melihat output berikut:
[[ -1.2594655 21.27488324][ 7.95762224 -20.76873116]
[ 6.99192123 -9.95598191]
…
[ 10.8012644 -6.96019661]
[ -4.87210598 12.42397516]
[ -0.34441647 6.36562581]]
[[ -1.25946526 21.27487934]
[ 7.95761543 -20.76870705]
[ 6.99191947 -9.9559785 ]
…
[ 10.80128422 -6.96025542]
[ -4.87210144 12.42396098]
[ -0.3443928 6.36555416]]
Dalam kode di atas, kami menyebutkan bahwa kami hanya membutuhkan 2 fitur untuk dataset.
Sekarang setelah kami memiliki pengetahuan yang baik tentang kumpulan data kami, kami dapat memutuskan jenis algoritma pembelajaran mesin apa yang dapat kami terapkan di dalamnya. Mengetahui kumpulan data penting karena dengan cara itulah kita dapat memutuskan informasi apa yang dapat diekstraksi darinya dan dengan algoritme apa. Ini juga membantu kami menguji hipotesis yang kami buat sambil memprediksi nilai masa depan.
Menerapkan pengelompokan k-means
Algoritma pengelompokan k-means adalah salah satu algoritma pengelompokan termudah untuk pembelajaran tanpa pengawasan. Dalam pengelompokan ini, kami memiliki beberapa jumlah cluster acak dan kami mengklasifikasikan titik data kami dalam satu cluster ini. Algoritma k-means akan menemukan cluster terdekat untuk setiap titik data yang diberikan dan menetapkan titik data tersebut ke cluster tersebut.
Setelah clustering selesai, pusat cluster dihitung ulang, titik-titik data diberikan cluster baru jika ada perubahan. Proses ini diulang sampai titik data berhenti mengubah cluster di sana untuk mencapai stabilitas.
Mari kita terapkan algoritme ini tanpa pemrosesan data sebelumnya. Untuk strategi ini, cuplikan kodenya akan cukup mudah:
dari kluster impor sklearnk = 3
k_means = cluster.KMeans(k)
# sesuai data
k_means.cocok (digit.data)
# hasil cetak
cetak(k_means.label_[::10])
cetak (digit.sasaran[::10])
Setelah kita menjalankan potongan kode di atas, kita akan melihat output berikut:
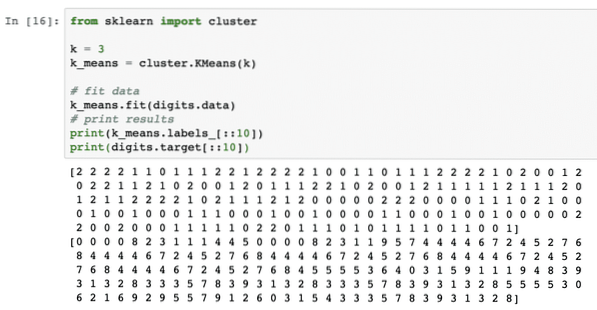
Dalam output di atas, kita dapat melihat cluster yang berbeda disediakan untuk masing-masing titik data.
Kesimpulan
Dalam pelajaran ini, kami melihat perpustakaan Machine Learning yang sangat baik, scikit-learn. Kami belajar bahwa ada banyak modul lain yang tersedia di keluarga scikit dan kami menerapkan algoritme k-means sederhana pada kumpulan data yang disediakan. Ada banyak lagi algoritma yang dapat diterapkan pada dataset selain dari k-means clustering yang kami terapkan dalam pelajaran ini, kami mendorong Anda untuk melakukannya dan membagikan hasil Anda.
Silakan bagikan umpan balik Anda tentang pelajaran di Twitter dengan @sbmaggarwal dan @LinuxHint.


