Panda .read_csv
Saya telah membahas beberapa sejarah dan kegunaan untuk panda perpustakaan Python. pandas dirancang karena kebutuhan akan analisis data keuangan yang efisien dan perpustakaan manipulasi untuk Python. Untuk memuat data untuk analisis dan manipulasi, pandas menyediakan dua metode:, Pembaca Data dan read_csv. Saya menutupi yang pertama di sini. Yang terakhir adalah subjek dari tutorial ini.
.read_csv
Ada sejumlah besar penyimpanan data online gratis yang mencakup informasi tentang berbagai bidang. Saya telah menyertakan beberapa sumber daya tersebut di bagian referensi di bawah. Karena saya telah mendemonstrasikan API bawaan untuk menarik data keuangan secara efisien di sini, saya akan menggunakan sumber data lain dalam tutorial ini.
Data.gov menawarkan banyak pilihan data gratis tentang segala hal mulai dari perubahan iklim hingga U.S. statistik manufaktur. Saya telah mengunduh dua kumpulan data untuk digunakan dalam tutorial ini. Yang pertama adalah suhu maksimum harian rata-rata untuk Bay County, Florida. Data ini diunduh dari U.S. Perangkat Ketahanan Iklim untuk periode 1950 hingga saat ini.
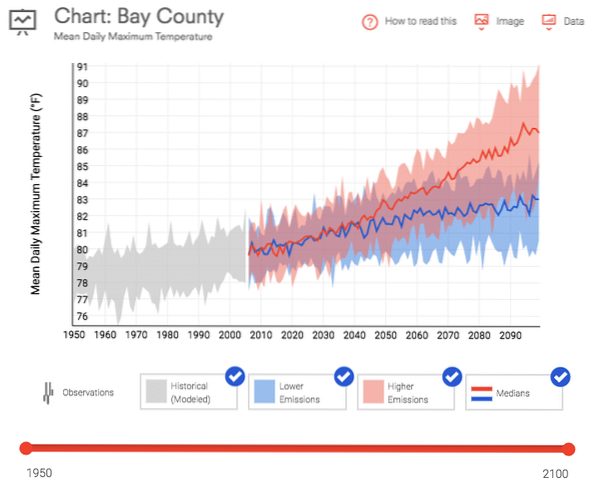
Yang kedua adalah Survei Arus Komoditas yang mengukur mode dan volume impor ke negara tersebut selama periode 5 tahun.

Kedua tautan untuk kumpulan data ini disediakan di bagian referensi di bawah ini. Itu .read_csv metode, seperti yang jelas dari namanya, akan memuat informasi ini dari file CSV dan instantiate a Bingkai Data dari kumpulan data itu.
Pemakaian
Setiap kali Anda menggunakan perpustakaan eksternal, Anda perlu memberi tahu Python bahwa itu perlu diimpor. Di bawah ini adalah baris kode yang mengimpor perpustakaan pandas.
impor panda sebagai pdPenggunaan dasar dari .read_csv caranya ada di bawah. Ini memberi contoh dan mengisi a Bingkai Data df dengan informasi dalam file CSV.
df = pd.read_csv('12005-annual-hist-obs-tasmax.csv')Dengan menambahkan beberapa baris lagi, kita dapat memeriksa 5 baris pertama dan terakhir dari DataFrame yang baru dibuat.
df = pd.read_csv('12005-annual-hist-obs-tasmax.csv')cetak(df.kepala(5))
cetak(df.ekor (5))

Kode telah memuat kolom untuk tahun, suhu harian rata-rata dalam Celcius (tasmax), dan membangun skema pengindeksan berbasis 1 yang meningkat untuk setiap baris data. Penting juga untuk dicatat bahwa header diisi dari file. Dengan penggunaan dasar metode yang disajikan di atas, header disimpulkan berada di baris pertama file CSV. Ini dapat diubah dengan meneruskan serangkaian parameter yang berbeda ke metode.
Parameter
Saya telah memberikan tautan ke panda .read_csv dokumentasi dalam referensi di bawah ini. Ada beberapa parameter yang dapat digunakan untuk mengubah cara data dibaca dan diformat dalam Bingkai Data.

Ada cukup banyak parameter untuk .read_csv metode. Sebagian besar tidak diperlukan karena sebagian besar kumpulan data yang Anda unduh akan memiliki format standar. Itu adalah kolom di baris pertama dan pembatas koma.
Ada beberapa parameter yang akan saya soroti dalam tutorial karena mereka dapat berguna. Survei yang lebih komprehensif dapat diambil dari halaman dokumentasi.
indeks_kol
indeks_kol adalah parameter yang dapat digunakan untuk menunjukkan kolom yang menyimpan indeks. Beberapa file mungkin berisi indeks dan beberapa mungkin tidak. Di kumpulan data pertama kami, saya membiarkan python membuat indeks. Ini standarnya .read_csv tingkah laku.
Dalam kumpulan data kedua kami, ada indeks yang disertakan. Kode di bawah ini memuat Bingkai Data dengan data dalam file CSV, tetapi alih-alih membuat indeks berbasis bilangan bulat tambahan, ia menggunakan kolom SHPMT_ID yang disertakan dalam kumpulan data.
df = pd.read_csv('cfs_2012_pumf_csv.txt', index_col = 'SHIPMT_ID')cetak(df.kepala(5))
cetak(df.ekor (5))
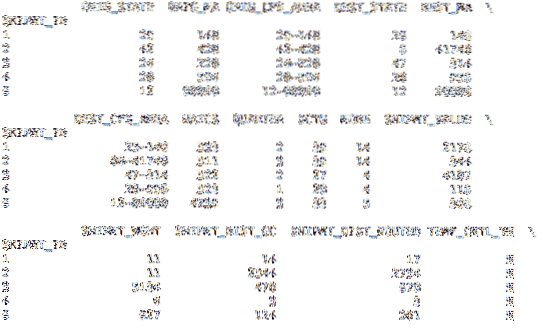
Meskipun kumpulan data ini menggunakan skema yang sama untuk indeks, kumpulan data lain mungkin memiliki indeks yang lebih berguna.
nrows, skiprows, usecols
Dengan kumpulan data besar, Anda mungkin hanya ingin memuat sebagian data. Itu menyempit, skiprows, dan usecols parameter akan memungkinkan Anda untuk mengiris data yang disertakan dalam file.
df = pd.read_csv('cfs_2012_pumf_csv.txt', index_col= 'SHIPMT_ID', nrows = 50)cetak(df.kepala(5))
cetak(df.ekor (5))
Dengan menambahkan menyempit parameter dengan nilai integer 50, the .panggilan ekor sekarang mengembalikan saluran hingga 50. Sisa data dalam file tidak diimpor.
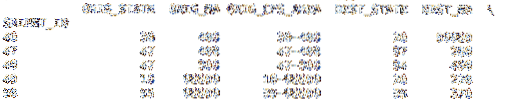
cetak(df.kepala(5))
cetak(df.ekor (5))
Dengan menambahkan skiprows parameter, kami .kepala col tidak menunjukkan indeks awal 1001 dalam data. Karena kami melewatkan baris header, data baru kehilangan header dan indeksnya berdasarkan data file file. Dalam beberapa kasus, mungkin lebih baik untuk mengiris data Anda dalam a Bingkai Data daripada sebelum memuat data.

Itu usecols adalah parameter berguna yang memungkinkan Anda mengimpor hanya sebagian data menurut kolom. Itu dapat melewati indeks ke-nol atau daftar string dengan nama kolom. Saya menggunakan kode di bawah ini untuk mengimpor empat kolom pertama ke yang baru Bingkai Data.
df = pd.read_csv('cfs_2012_pumf_csv.txt',index_col = 'SHIPMT_ID',
nrows = 50, usecols = [0,1,2,3] )
cetak(df.kepala(5))
cetak(df.ekor (5))
Dari baru kami .kepala panggilan, kami Bingkai Data sekarang hanya berisi empat kolom pertama dari kumpulan data.
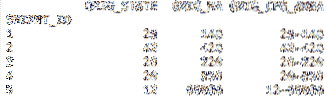
mesin
Satu parameter terakhir yang menurut saya akan berguna di beberapa kumpulan data adalah mesin parameter. Anda dapat menggunakan mesin berbasis C atau kode berbasis Python. Mesin C secara alami akan lebih cepat. Ini penting jika Anda mengimpor kumpulan data besar. Manfaat dari penguraian Python adalah kumpulan yang lebih kaya fitur. Manfaat ini mungkin kurang berarti jika Anda memuat data besar ke dalam memori.
df = pd.read_csv('cfs_2012_pumf_csv.txt',index_col = 'SHIPMT_ID', mesin = 'c' )
cetak(df.kepala(5))
cetak(df.ekor (5))
Mengikuti
Ada beberapa parameter lain yang dapat memperluas perilaku default dari .read_csv metode. Mereka dapat ditemukan di halaman dokumen yang saya rujuk di bawah ini. .read_csv adalah metode yang berguna untuk memuat kumpulan data ke dalam panda untuk analisis data. Karena banyak kumpulan data gratis di internet tidak memiliki API, ini akan terbukti paling berguna untuk aplikasi di luar data keuangan di mana ada API yang kuat untuk mengimpor data ke dalam panda.
Referensi
https://pandas.pidata.org/pandas-docs/stable/generated/pandas.read_csv.html
https://www.data.pemerintah/
https://toolkit.iklim.gov/#climate-explorer
https://www.sensus.gov/econ/cfs/pums.html


