Apache Spark adalah alat analisis data yang dapat digunakan untuk memproses data dari HDFS, S3 atau sumber data lain di memori. Dalam posting ini, kami akan menginstal Apache Spark di Ubuntu 17.10 mesin.
Versi Ubuntu
Untuk panduan ini, kami akan menggunakan Ubuntu versi 17.10 (GNU/Linux 4.13.0-38-generik x86_64).
Apache Spark adalah bagian dari ekosistem Hadoop untuk Big Data. Coba Instal Apache Hadoop dan buat contoh aplikasi dengannya.
Memperbarui paket yang ada
Untuk memulai penginstalan Spark, kami perlu memperbarui mesin kami dengan paket perangkat lunak terbaru yang tersedia. Kita dapat melakukannya dengan:
sudo apt-get update && sudo apt-get -y dist-upgradeKarena Spark berbasis Java, kami perlu menginstalnya di mesin kami. Kami dapat menggunakan versi Java apa pun di atas Java 6. Di sini, kita akan menggunakan Java 8:
sudo apt-get -y install openjdk-8-jdk-headlessMengunduh file Spark
Semua paket yang diperlukan sekarang ada di mesin kami. Kami siap mengunduh file Spark TAR yang diperlukan sehingga kami dapat mulai menyiapkannya dan menjalankan program sampel dengan Spark juga.
Dalam panduan ini, kami akan menginstal Percikan v2.3.0 Tersedia disini:
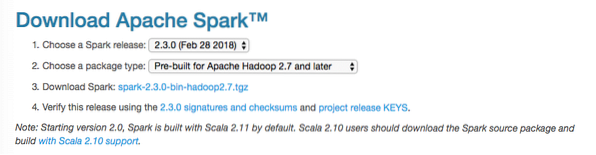
Halaman unduhan percikan
Unduh file yang sesuai dengan perintah ini:
wget http://www-us.apache.org/dist/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgzBergantung pada kecepatan jaringan, ini bisa memakan waktu hingga beberapa menit karena file berukuran besar:
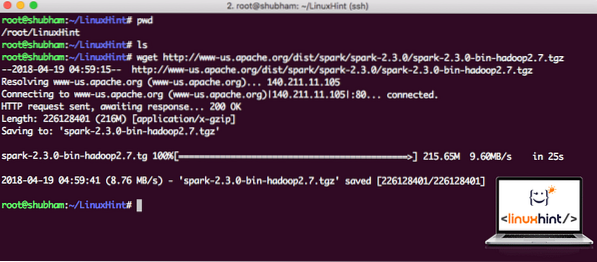
Mengunduh Apache Spark
Sekarang kita memiliki file TAR yang diunduh, kita dapat mengekstraknya di direktori saat ini:
tar xvzf percikan-2.3.0-bin-hadoop2.7.tgzIni akan memakan waktu beberapa detik untuk diselesaikan karena ukuran file arsip yang besar:
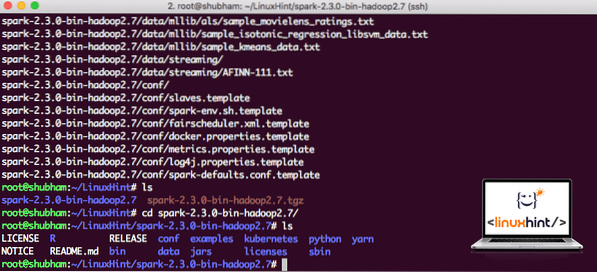
File yang tidak diarsipkan di Spark
Ketika datang untuk memutakhirkan Apache Spark di masa depan, itu dapat menimbulkan masalah karena pembaruan Path. Masalah ini dapat dihindari dengan membuat tautan lunak ke Spark. Jalankan perintah ini untuk membuat softlink:
ln -s percikan-2.3.0-bin-hadoop2.7 percikanMenambahkan Spark ke Path
Untuk menjalankan skrip Spark, kami akan menambahkannya ke jalur sekarang. Untuk melakukan ini, buka file bashrc:
vi ~/.bashrcTambahkan baris ini ke akhir ..bashrc file sehingga jalur dapat berisi jalur file yang dapat dieksekusi Spark:
SPARK_HOME=/LinuxHint/sparkekspor PATH=$SPARK_HOME/bin:$PATH
Sekarang, file tersebut terlihat seperti:
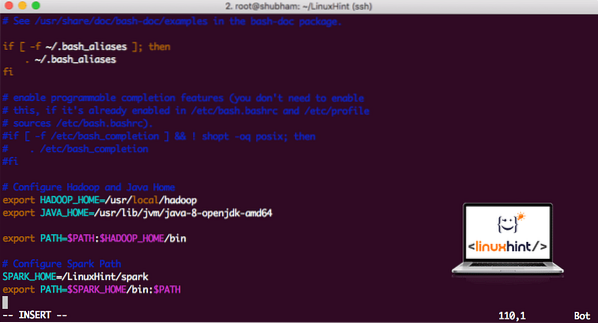
Menambahkan Spark ke PATH
Untuk mengaktifkan perubahan ini, jalankan perintah berikut untuk file bashrc:
sumber ~/.bashrcMeluncurkan Spark Shell
Sekarang ketika kita berada tepat di luar direktori spark, jalankan perintah berikut untuk membuka shell apark:
./spark/bin/spark-shellKita akan melihat bahwa Spark shell terbuka sekarang:
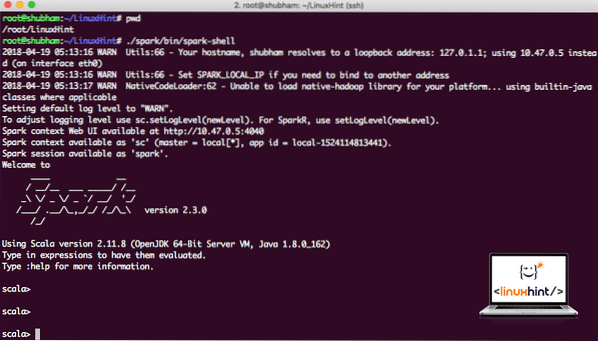
Meluncurkan Spark shell
Kita dapat melihat di konsol bahwa Spark juga telah membuka Konsol Web pada port 404. Mari kita kunjungi:
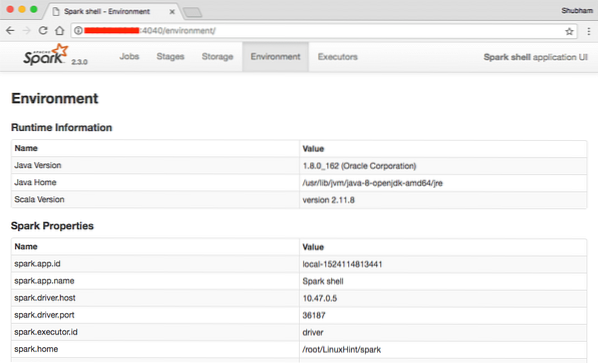
Konsol Web Apache Spark
Meskipun kami akan beroperasi di konsol itu sendiri, lingkungan web adalah tempat penting untuk dilihat saat Anda menjalankan Spark Job yang berat sehingga Anda tahu apa yang terjadi di setiap Spark Job yang Anda jalankan.
Periksa versi Spark Shell dengan perintah sederhana:
sc.Versi: kapanKami akan mendapatkan kembali sesuatu seperti:
res0: String = 2.3.0Membuat Contoh Aplikasi Spark dengan Scala
Sekarang, kita akan membuat contoh aplikasi Word Counter dengan Apache Spark. Untuk melakukan ini, pertama-tama muat file teks ke dalam Spark Context pada Spark shell:
scala> var Data = sc.textFile("/root/LinuxHint/spark/README.md")Data: org.apache.percikan.rdd.RDD[String] = /root/LinuxHint/spark/README.md MapPartitionsRDD[1] di textFile at :24
skala>
Sekarang, teks yang ada dalam file harus dipecah menjadi token yang dapat dikelola Spark:
scala> var token = Data.flatMap(s => s.membagi (" "))token: org.apache.percikan.rdd.RDD[String] = MapPartitionsRDD[2] di flatMap di :25
skala>
Sekarang, inisialisasi hitungan untuk setiap kata menjadi 1:
scala> var token_1 = token token.peta(s => (s,1))token_1: org.apache.percikan.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] pada peta pada :25
skala>
Akhirnya, hitung frekuensi setiap kata dari file:
var sum_each = token_1.mengurangiByKey((a, b) => a + b)Saatnya melihat output untuk program. Kumpulkan token dan jumlah masing-masing:
skala> jumlah_setiap_.mengumpulkan()res1: Array[(String, Int)] = Array((paket,1), (Untuk,3), (Program,1), (memproses.,1), (Karena,1), (The,1), (halaman](http://spark.apache.org/dokumentasi.html).,1), (kelompok.,1), (its,1), ([run,1), (dari,1), (APIs,1), (memiliki,1), (Coba,1), (komputasi,1), (melalui,1 ), (beberapa,1), (Ini,2), (grafik,1), (Sarang,2), (penyimpanan,1), (["Menentukan,1), (Ke,2), ("benang" ,1), (Sekali,1), (["Berguna,1), (lebih disukai,1), (SparkPi,2), (mesin,1), (versi,1), (file,1), (dokumentasi ,,1), (memproses,,1), (the,24), (adalah,1), (sistem.,1), (params,1), (bukan,1), (berbeda,1), (rujuk,2), (Interaktif,2), (R,,1), (diberikan.,1), (jika,4), (membangun,4), (kapan,1), (menjadi,2), (Tes,1), (Apache,1), (utas,1), (program,,1 ), (termasuk,4), (./bin/run-example,2), (Spark.,1), (paket.,1), (1000).count(),1), (Versi,1), (HDFS,1), (D…
skala>
Luar biasa! Kami dapat menjalankan contoh Penghitung Kata sederhana menggunakan bahasa pemrograman Scala dengan file teks yang sudah ada di sistem.
Kesimpulan
Dalam pelajaran ini, kita melihat bagaimana kita dapat menginstal dan mulai menggunakan Apache Spark di Ubuntu 17.10 mesin dan jalankan aplikasi sampel di atasnya juga.
Baca lebih banyak posting berbasis Ubuntu di sini.

